If you’ve spent time working in QA automation, you know the frustration of flaky tests. Those intermittent failures that appear out of nowhere, often in CI/CD pipelines, can make you question the stability of your environment, your framework, and even your sanity. I’ve been there—watching a test fail five times in a row on a sunny Tuesday morning, only to pass perfectly when run locally.
In my early SDET days, flaky tests were a constant thorn in our release cycle. Every failure triggered panic: was it a real bug, or just an environmental hiccup? Developers were hesitant to trust our results, and our pipeline’s credibility was slipping. That’s when we discovered the power of retry logic. Implementing it transformed not just our test reliability but the confidence of the entire QA and Dev teams. Here’s my journey in leveraging retry logic in CI/CD and why it’s a game-changer for handling flaky tests.
Understanding the Root Cause of Flaky Tests
Before diving into retry logic, we had to understand why tests were flaky. In our environment, failures usually stemmed from one of these issues:
- Network or API Latency
Sometimes, tests failed because responses from backend services were slightly delayed. A simple assertEquals() would fail if the response didn’t arrive within a hard-coded timeout.
- Environment Instability
Our preprod servers occasionally threw 404 or 500 errors due to deployment timing or server load. Even perfectly written tests couldn’t account for these transient issues.
- Third-Party Dependencies
Some tests relied on services outside our control—payment gateways, external APIs, or region-specific banker profiles. If these services were slow or unavailable, tests failed unpredictably.
- Timing Issues on UI
Elements loaded asynchronously on pages, and despite using explicit waits, some assertions would fail sporadically because of rendering delays.


In short, flaky tests are rarely about bad automation code—they’re often environmental or timing-related. Recognizing this was key to designing a solution that didn’t compromise test integrity.
Don’t Miss Out: automation testing interview questions
The Initial Pain
Before we implemented retry logic, our CI/CD pipeline had no tolerance for flaky tests. A single failure would halt the pipeline, triggering:
- Alarm emails and Slack notifications
- Manual intervention to analyze whether the failure was real
- Re-execution of the same test or entire suite, consuming hours
- Delays in deployment and frustration among developers and QA
The manual approach was time-consuming and unreliable. We needed a way to filter out noise while keeping genuine failures visible.
Enter Retry Logic
Retry logic is a simple yet powerful mechanism: if a test fails, it’s automatically retried a fixed number of times before being marked as failed. This small adjustment made a huge difference:
- Mitigating Environmental Flakiness
Tests that failed due to temporary server issues, slow API responses, or network hiccups were automatically retried. Most of the time, they passed on subsequent attempts, ensuring valid failures surfaced. - Reducing False Negatives
Previously, a test might fail for a minor reason unrelated to the application’s functionality. Retry logic gave tests a chance to recover from transient conditions, making CI/CD results more reliable. - Saving Manual Effort
QA no longer had to re-run failed tests manually to distinguish real bugs from flaky failures. This freed up hours every week for exploratory testing and writing new automation.


More Insights: api automation testing interview questions
How We Implemented Retry Logic
Our implementation had a few guiding principles:
1. Controlled Retries
We decided not to retry indefinitely. Each test had a maximum retry count of 5. This ensured that:
- Truly failing tests were still reported
- The pipeline didn’t get stuck in endless retries
- Environmental issues had enough attempts to pass if transient
2. Logging and Visibility
We didn’t want retries to hide failures silently. Every retry attempt was logged with details:
- Test name and step
- Failure reason (assertion message, exception)
- Attempt count
This visibility helped developers and QA understand whether a test failed due to code, environment, or timing.
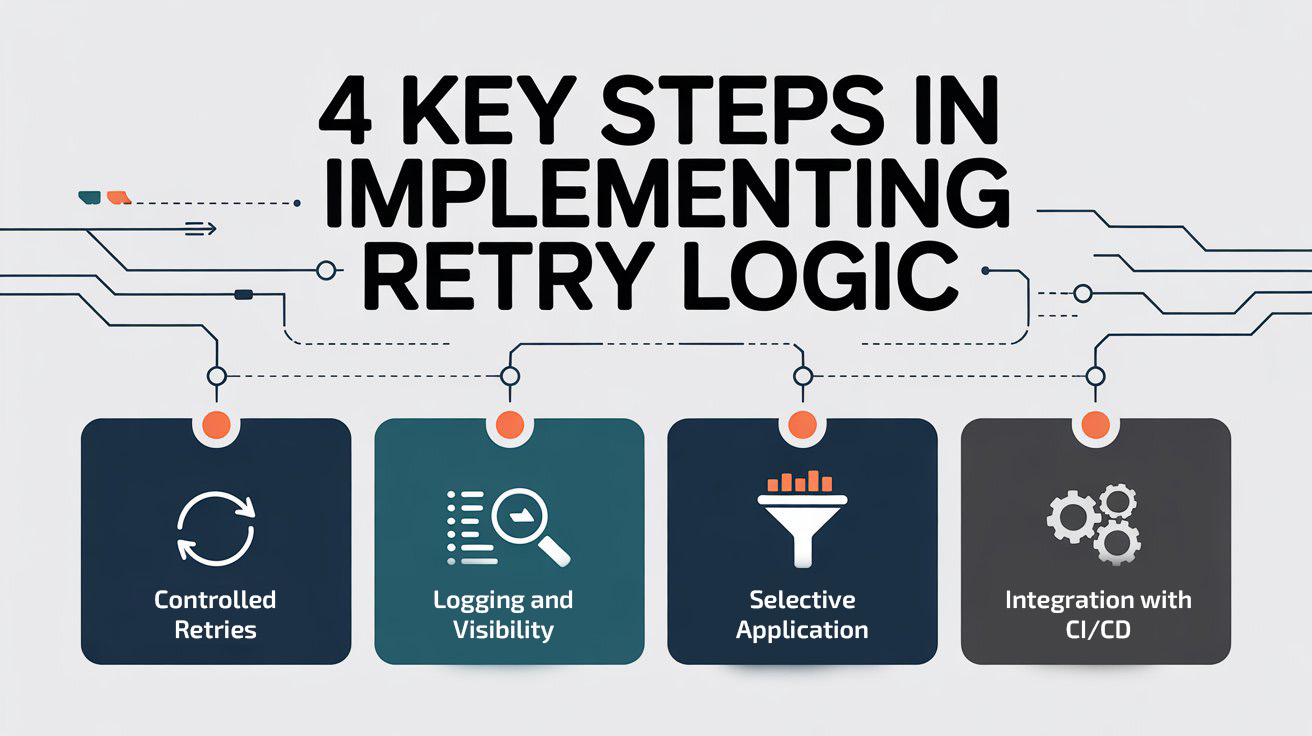
3. Selective Application
Not all tests are created equal. Critical workflow tests were eligible for retries, but exploratory or low-priority tests were excluded. This saved pipeline time and focused attention on high-value scenarios.
4. Integration with CI/CD
Retry logic was fully integrated into our Azure DevOps pipeline. Each test stage—Dev, QA, Preprod—benefited from retries, and reports clearly showed initial failures versus final outcome after retries. Developers could trust that a failure marked as final was likely a real issue.
Explore More: playwright interview questions
Lessons Learned from Retry Logic
1. Retry Logic Does Not Replace Fixes
Retries help mitigate environmental flakiness, but they don’t fix root causes. During implementation, we still monitored flaky tests closely to:
- Identify patterns (e.g., specific APIs or regions causing failures)
- Collaborate with Dev teams to resolve recurring issues
Retry logic is a safety net, not a crutch.
2. Balance Between Stability and Speed
Retries increase pipeline execution time. To avoid excessive delays, we:
- Limited retry attempts to 5
- Parallelized retries when possible
- Prioritized high-impact tests for retries
This balance ensured stability without slowing down delivery.

3. Data and Network Awareness
Retries were most effective when combined with network logs and HAR files. By analyzing failed attempts, we could determine whether the failure was a real defect or a transient network glitch.
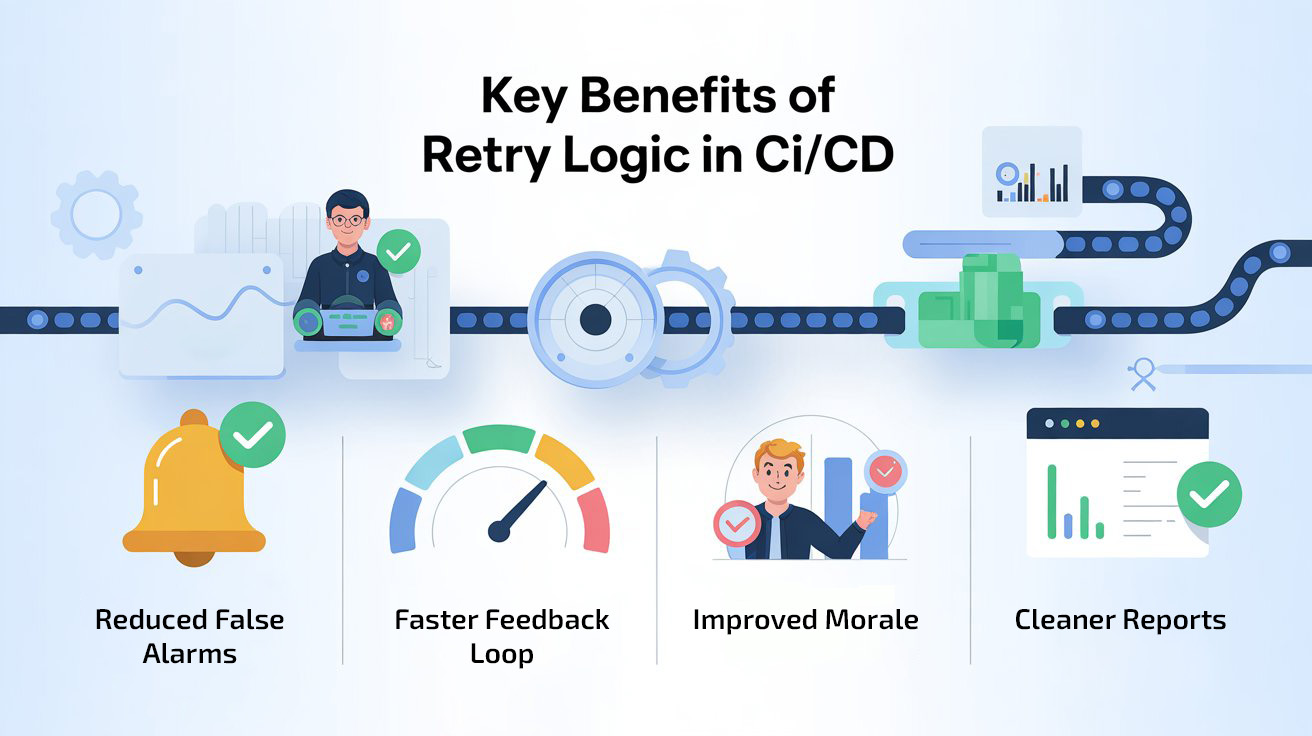
The Impact on Our QA Process
The difference was immediate and measurable:
- Reduced False Alarms
Flaky failures dropped by over 60%, reducing unnecessary investigation and re-runs. - Faster Feedback Loop
Developers received trustworthy CI/CD results, allowing faster bug fixes and shorter release cycles. - Improved Morale
QA felt empowered knowing that pipeline failures were meaningful, not random. The Dev team also gained confidence in automation results. - Cleaner Reports
Our test reports clearly distinguished between first-attempt failures and final outcomes after retries, making it easy to analyze trends and track improvements.
Conclusion
Flaky tests can erode trust in automation if not handled properly. Retry logic, when implemented thoughtfully, provides a practical solution: it filters out noise, surfaces real issues, and ensures CI/CD pipelines remain reliable.
From my perspective, retry logic is a secret weapon in the QA toolkit. It doesn’t fix the environment or third-party dependencies, but it gives your tests a fighting chance to pass under imperfect conditions. Combined with good logging, HAR file analysis, and selective application, it transforms flaky tests from a constant headache into a manageable challenge.
For any SDET navigating the chaos of CI/CD, my advice is simple: implement retry logic, monitor patterns, and keep iterating. It’s a small change with a huge payoff for automation stability and team confidence.
FAQs
1. What is retry logic in CI/CD?
Retry logic automatically re-runs failed tests a set number of times to eliminate environmental or timing-related failures, improving test reliability.
2. Why do flaky tests occur in automation?
Flaky tests are usually caused by API latency, unstable environments, asynchronous UI load issues, and third-party dependencies—not by test script errors alone.
3. Does retry logic fix flaky tests completely?
No. Retry logic filters out transient failures, but root causes such as performance issues, unstable environments, or API delays still need investigation.
4. How many retry attempts should a pipeline allow?
Most teams use 2–5 retries. Too many retries increase execution time, while too few might not catch environmental inconsistencies.
5. Does retry logic slow down CI/CD pipelines?
It adds minor overhead, but improved accuracy, reduced false alarms, and fewer manual re-runs save far more time overall.
We Also Provide Training In:
- Advanced Selenium Training
- Playwright Training
- Gen AI Training
- AWS Training
- REST API Training
- Full Stack Training
- Appium Training
- DevOps Training
- JMeter Performance Training
Author’s Bio:


Content Writer at Testleaf, specializing in SEO-driven content for test automation, software development, and cybersecurity. I turn complex technical topics into clear, engaging stories that educate, inspire, and drive digital transformation.
Ezhirkadhir Raja
Content Writer – Testleaf
![]()