


Your Selenium test passes locally.
It fails in CI.
You rerun the pipeline — and suddenly it passes.
Nothing changed in the code. Nothing changed in the test. Yet the result changed.
Welcome to the world of flaky tests.
For many engineering teams, flaky automation tests are one of the most frustrating hidden problems in modern software delivery. They slow down CI pipelines, waste engineering time, and eventually erode trust in automation itself.
And once developers stop trusting test results, automation loses its value.
The good news is that flaky tests are not inevitable. They are usually symptoms of deeper design issues in the automation system — issues that can be solved with the right engineering principles.
In this article, we’ll explore why flaky Selenium tests occur and the key reliability patterns engineering teams use to stabilize their automation suites.
Why do Selenium tests pass locally but fail in CI?
Selenium tests often fail in CI because of timing issues, shared test data, unstable environments, or race conditions caused by parallel execution. These problems lead to flaky tests that behave inconsistently across environments.
Key Takeaways
-
Flaky Selenium tests usually result from timing issues and shared state.
-
Parallel execution increases the chance of race conditions.
-
Test isolation is essential for stable automation pipelines.
-
Retry wrappers should be used carefully to detect transient failures.
-
Reliable automation requires deterministic and repeatable test design.
Other Helpful Articles: Automation testing interview questions
The Growing Problem of Flaky Tests in Modern CI Pipelines
Flaky tests are not a small annoyance. They are a large-scale engineering challenge.
Research from engineering teams at major tech companies has shown that a significant portion of CI test failures are caused not by real product defects but by unstable tests themselves.
In fast-moving DevOps environments, this leads to several problems:
- Developers rerun pipelines multiple times to get a green build
- CI/CD pipelines become slower and more expensive
- Engineers spend hours investigating false failures
- Automation results become less trustworthy
In other words, flaky tests create noise in the engineering feedback loop.
In an era of continuous deployment and rapid releases, reliable automation is no longer optional — it is foundational.
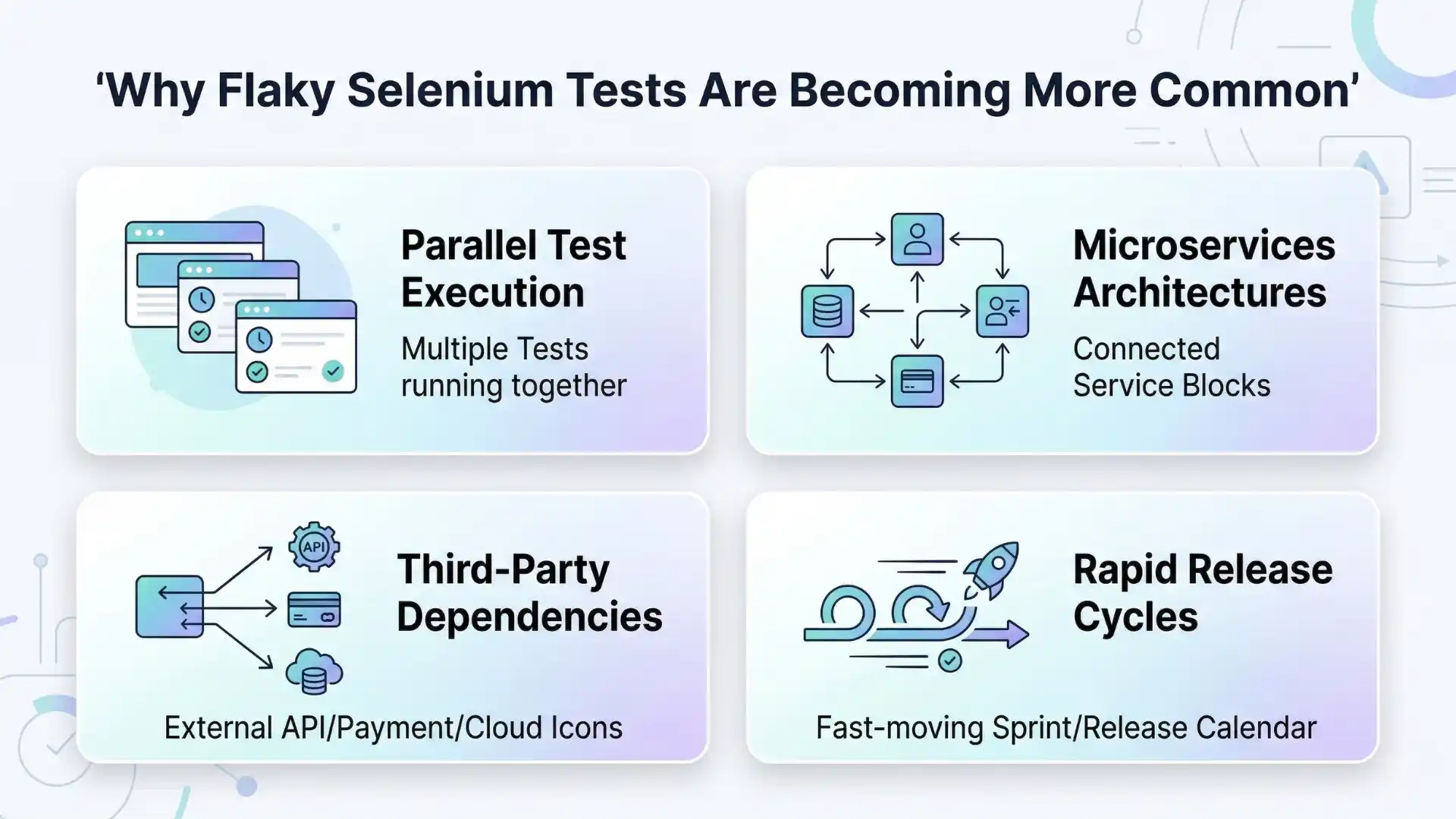
Why Flaky Selenium Tests Are Becoming More Common
Modern software architectures make test stability harder than before.
Several trends contribute to increasing test instability.
1. Parallel Test Execution
CI pipelines often execute dozens or hundreds of tests simultaneously to speed up builds.
When tests share data or environments, parallel execution introduces race conditions.
2. Microservices Architectures
Modern applications rely on multiple services communicating across networks.
Temporary service delays or API latency can cause unpredictable behavior.
3. Third-Party Dependencies
External systems such as payment gateways, analytics platforms, or authentication providers introduce variability outside the control of the test environment.
4. Rapid Release Cycles
Continuous integration means tests run more frequently than ever before.
Even small timing issues or unstable assumptions surface quickly.

Because of these factors, test automation must be designed for reliability, not just functionality.
Continue Reading: Top 10 product based companies in chennai
Common Causes of Flaky Selenium Tests
| Cause | Example | Fix |
|---|---|---|
| Timing Issues | Elements load slower in CI | Use explicit waits |
| Shared Data | Tests using same user account | Generate unique test data |
| Parallel Execution | Race conditions between tests | Isolate tests |
| External Services | Payment gateway latency | Use mocks/stubs |
| Unstable Environments | Network delays | Add retry logic carefully |
Three Engineering Patterns That Stabilize Selenium Test Suites
While flaky tests have many causes, experienced automation engineers consistently rely on three reliability patterns:
- Retry Wrappers
- Idempotent Test Actions
- Test Isolation
Together, these patterns form the foundation of stable automation systems.
1. Retry Wrappers — Handling Transient Failures Carefully
Retry logic is often misunderstood.
Many teams try to solve flaky tests by simply adding retries everywhere.
But blind retries hide real problems and create false confidence.
When used correctly, retry wrappers help handle transient failures, such as:
- Temporary network latency
- Slow UI rendering
- Momentary infrastructure issues in CI environments
Instead of failing immediately, a retry wrapper attempts the operation again a limited number of times.
However, good engineering practice requires:
- Limiting retries (usually 1–2 attempts)
- Logging retry events for investigation
- Retrying only safe operations
Retries should be treated as diagnostic signals, not permanent solutions.
If a test frequently passes only after retries, it indicates an underlying reliability issue that must be addressed.
2. Idempotent Test Actions — Making Automation Safe to Repeat
A concept borrowed from distributed systems engineering, idempotency plays a critical role in reliable test automation.
An action is idempotent if repeating it multiple times produces the same final state.
For example:
- Navigating to a dashboard page
• Ensuring a user is logged in
• Verifying a feature toggle is enabled
These actions can be safely repeated without breaking test logic.
In contrast, non-idempotent actions create risk when retried.
Examples include:
- Clicking “Add to Cart” multiple times
• Submitting a payment
• Creating duplicate records
Designing automation flows with idempotent steps ensures that retries do not accidentally corrupt test data or system state.
This simple design principle dramatically improves test stability.
3. Test Isolation — Preventing Tests From Interfering With Each Other
Another major cause of flaky tests is shared state.
When tests depend on shared users, shared records, or shared environments, they can interfere with each other — especially during parallel execution.
Effective test isolation includes several practices.
Unique Test Data
Each test should generate its own data, such as:
- Unique usernames
- Timestamped records
- Dynamic email addresses
This prevents collisions between concurrent tests.
Clean Environment Setup
Tests should create the data they need instead of relying on existing records in the environment.
Using APIs or database seeding can speed up setup while ensuring consistency.
Independent Test Execution
Every test should be runnable independently.
Tests that depend on execution order create cascading failures.
If one test fails, many others fail for the wrong reason.
Isolation ensures that each test validates a single behavior without interference from others.
You Might Also Like: manual testing interview questions
The Hidden Cost of Flaky Tests
Flaky automation tests create more than just technical problems.
They introduce economic costs to engineering organizations.
Developers waste time rerunning pipelines.
CI infrastructure usage increases.
Engineering productivity decreases.
Most importantly, teams lose trust in automation results.
Once that trust disappears, automation stops serving its primary purpose: providing fast and reliable feedback about product quality.
A Practical Flaky Test Stabilization Checklist
When investigating a flaky Selenium test, consider the following checklist.
✔ Replace hard waits (Thread.sleep) with explicit waits
✔ Ensure tests generate unique data
✔ Avoid retries around irreversible operations
✔ Investigate tests that pass only after retry
✔ Keep tests independent and order-agnostic
✔ Break large end-to-end tests into smaller validations
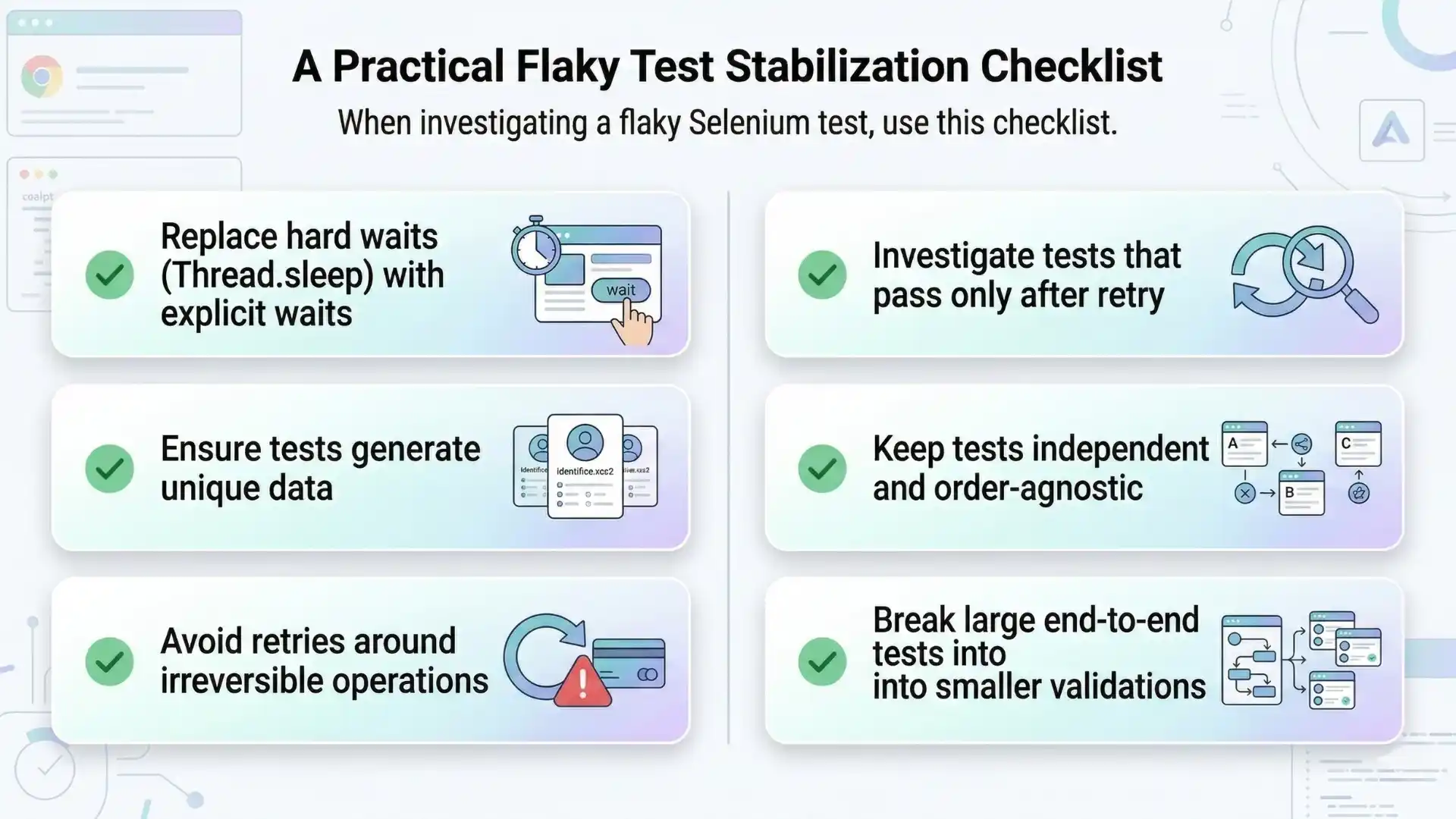
Applying these practices consistently can transform unstable test suites into reliable quality gates.
The Future of Reliable Automation
As software systems grow more complex, automation reliability will become even more important.
Emerging trends in quality engineering include:
- AI-assisted failure analysis
- Intelligent test prioritization in CI pipelines
- Predictive flake detection
- Automated root-cause classification
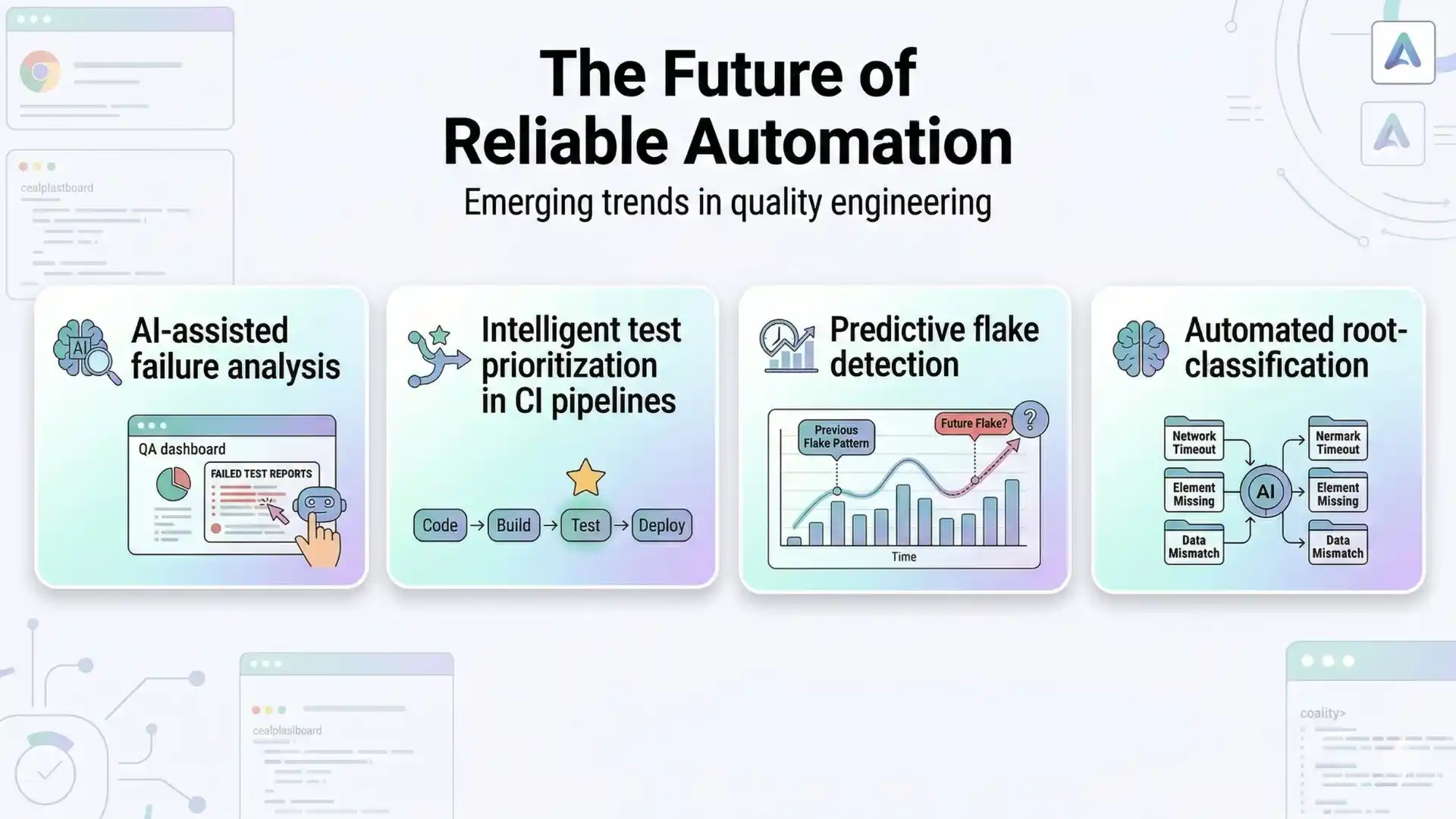
These innovations will help engineering teams detect instability faster and maintain healthier automation systems.
But regardless of tooling, the core principles remain the same:
Design automation for determinism, isolation, and repeatability.
Best Practices to Prevent Flaky Selenium Tests
-
Avoid using
Thread.sleep()in automation scripts -
Use explicit waits for dynamic elements
-
Ensure each test creates its own data
-
Run tests independently without execution order dependency
-
Monitor flaky test patterns in CI reports
Final Thoughts
Flaky Selenium tests are not simply testing annoyances—they are engineering reliability problems. As automation becomes the backbone of modern CI/CD pipelines, stable test design becomes critical.
Organizations that invest in test isolation, deterministic automation flows, and reliable CI environments will see faster builds, higher developer confidence, and more trustworthy automation results. Many QA professionals strengthen these reliability practices by gaining deeper practical knowledge through structured learning such as Selenium training in chennai, where real-world automation challenges are addressed.
The future of automation testing will not be defined by the number of tests executed, but by how consistently those tests deliver reliable feedback.
FAQs
What is a flaky Selenium test?
Why do Selenium tests fail in CI pipelines?
How can you fix flaky Selenium tests?
Are flaky tests common in automation testing?
We Also Provide Training In:
- Advanced Selenium Training
- Playwright Training
- Gen AI Training
- AWS Training
- REST API Training
- Full Stack Training
- Appium Training
- DevOps Training
- JMeter Performance Training
Author’s Bio:


Content Writer at Testleaf, specializing in SEO-driven content for test automation, software development, and cybersecurity. I turn complex technical topics into clear, engaging stories that educate, inspire, and drive digital transformation.
Ezhirkadhir Raja
Content Writer – Testleaf
![]()









