
When I first started working as a tester, one of the biggest mistakes I made (and saw others make) was relying on hard-coded test data in our automation scripts. At the time, it seemed like the quickest way to get tests running: plug in a username, password, or account number directly into the script and move on.
But as our test suite grew, this shortcut became a nightmare. Tests were fragile, hard to maintain, and full of duplication. Any small change in data meant dozens of scripts had to be updated. Eventually, this approach started slowing us down more than helping us.
That’s when we decided to rethink how we managed test data. The solution? A centralized test data strategy that eliminated hardcoding, improved consistency, and made our framework more stable than ever.
Let me take you through what went wrong with hard-coded data, how we fixed it, and the impact it had on our QA process.
The Chaos of Hard-Coded Data
Here’s what we were struggling with when we used hard-coded data in our tests:
1. Brittle Tests
If a test script used a specific account number like 12345 or an email like testuser@example.com, it would work fine—until that data changed. If the account was deleted, locked, or modified, the test would fail for the wrong reason.
2. Duplication Everywhere
We had dozens of scripts repeating the same data. If a password changed, we had to update it in multiple places. It was error-prone and tedious.
3. Scalability Issues
Hard-coded data might work for a handful of scripts, but once you have hundreds of tests, it becomes unmanageable. One small change could break the entire suite.
4. No Flexibility for Regions or Environments
Since our product supported multiple regions and environments (QA, Preprod, Prod), hard-coded values tied the tests to a specific environment. Running the same suite in another region meant rewriting or duplicating scripts.
5. Poor Debugging Experience
When a test failed, it wasn’t always clear whether it was a product bug or just bad data. Hardcoded values blurred the line, causing wasted effort during triage.

More Insights: product based companies in chennai
The Breaking Point
The real chaos hit during a major release cycle. Several of our regression tests failed—not because of new bugs, but because the hardcoded data we’d been relying on no longer existed in the environment. We wasted an entire day trying to fix failing scripts, only to realize the problem wasn’t with the product, but with our own test data management.
That’s when I knew we couldn’t keep patching things. We had to kill hard-coded data once and for all.
The Shift: A Centralized Test Data Strategy
We set out to build a centralized test data solution that any test could consume without worrying about hardcoding. Here’s how we approached it step by step:
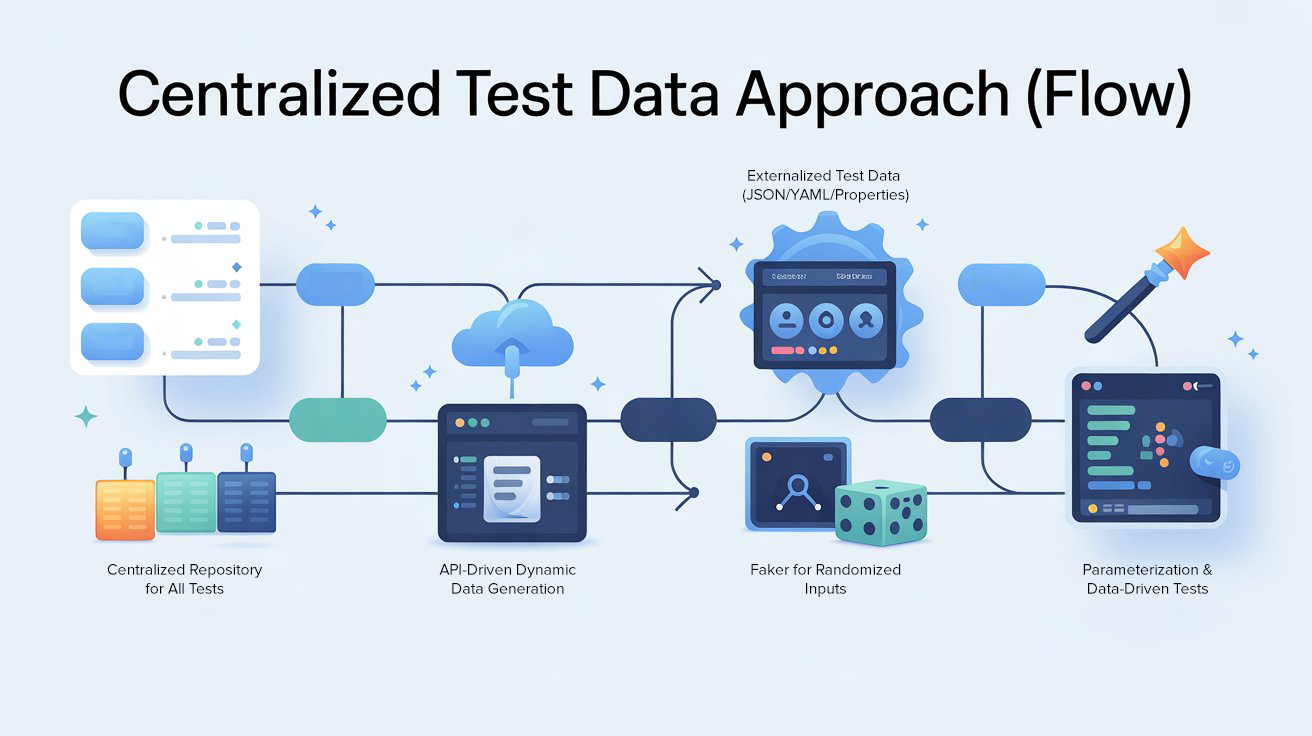
1. Externalized Test Data
The first step was moving test data out of scripts and into external files—JSON, YAML, or property files. This allowed us to separate logic from data. Scripts now referenced variables, not literal values.
Example:
{
“qa”: {
“username”: “qa_user”,
“password”: “qa_pass”
},
“preprod”: {
“username”: “preprod_user”,
“password”: “preprod_pass”
}
}
This made it easy to switch environments by simply pointing to the right config.
2. Centralized Repository
Instead of having multiple scattered data files, we created a centralized repository where all test data lived. Every test script pulled data from this repository, ensuring consistency across the suite.
Now, if a password or account number changed, we updated it once, and all tests immediately reflected the change.

3. API-Driven Dynamic Data
Static data still had limitations, especially when we needed unique or frequently changing data like customer IDs, orders, or session tokens. For this, we integrated with APIs that generated dynamic test data on demand.
For example:
- /generate/customer returned a new customer profile.
- /generate/order created a fresh order for validation.
This removed the dependency on stale hard-coded records and gave us flexibility.
4. Faker for Randomized Inputs
To add realism, we incorporated Faker for generating names, emails, phone numbers, and addresses. Instead of using the same hard-coded “John Doe” across tests, we could generate unique yet valid data every time.
This improved coverage and reduced conflicts when multiple tests ran in parallel.
5. Parameterization & Data-Driven Tests
We updated our test framework (using TestNG) to support parameterized tests. Instead of writing one script for every scenario, we wrote a single test and passed different data sets into it.
This drastically reduced the number of scripts we had to maintain, while increasing coverage.
Other Useful Guides: api automation interview questions
The Benefits We Saw
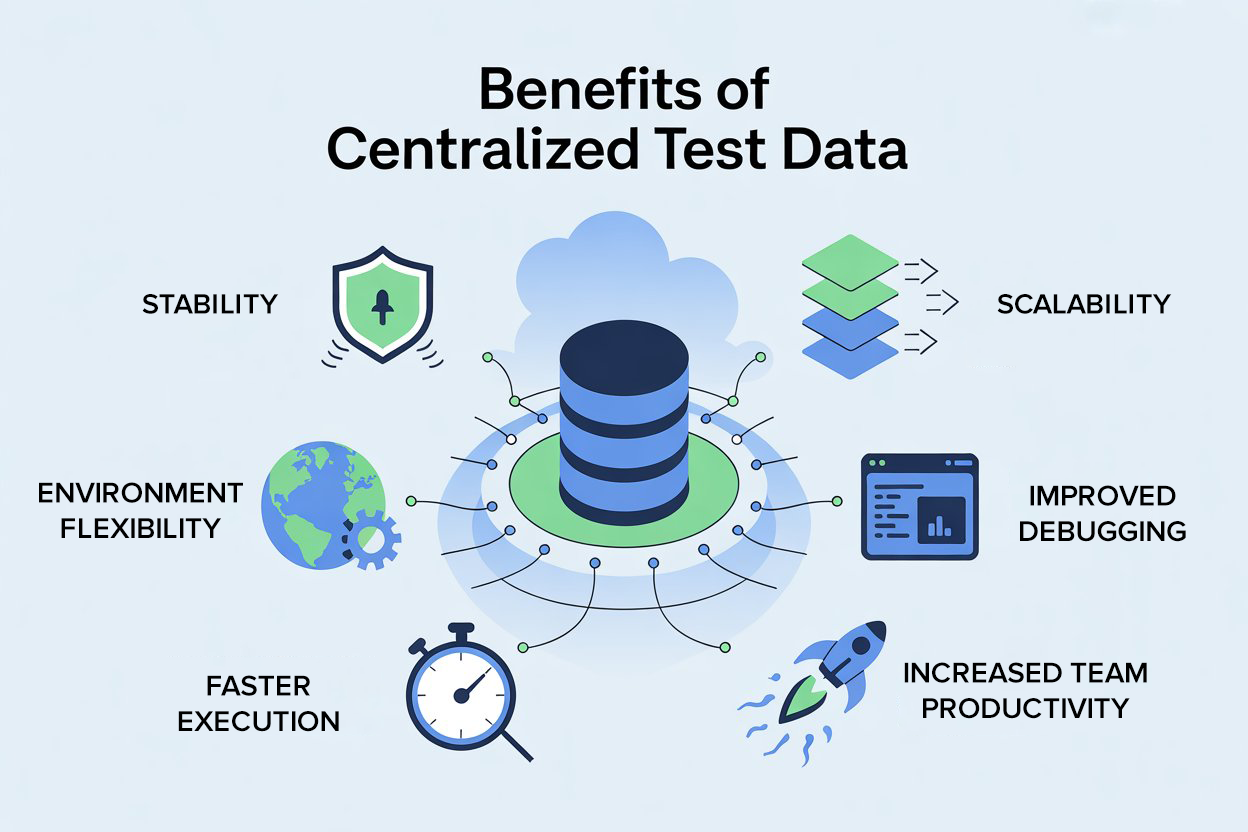
Moving to a centralized test data strategy changed everything for us. Here are the biggest wins:
1. Stability
No more false failures due to missing or outdated hard-coded values. Our tests became more reliable.
2. Scalability
As the number of tests grew, managing data didn’t become harder—it became easier. Updating one file or endpoint updated the entire suite.
3. Environment Flexibility
We could run the same suite across QA, Preprod, and Prod by just switching the config file. No rewriting scripts.
4. Improved Debugging
When tests failed, we knew it wasn’t because of stale data. This made debugging faster and gave developers more confidence in reported defects.
5. Faster Execution
By removing dependencies on manual updates, our regression runs became faster and smoother. Test data was always available and up-to-date.
6. Team Productivity
Instead of wasting time maintaining scripts, our testers could focus on writing new scenarios and increasing coverage.
Check Out These Articles: Selenium interview questions
Lessons Learned
Looking back, here are some lessons I learned from killing hard-coded data:
- Shortcuts don’t scale. Hardcoding works only for proof of concept, not for real frameworks.
- Separation of concerns is key. Keep test logic and test data separate—it improves maintainability.
- Centralization reduces chaos. Having one source of truth for data makes collaboration easier.
- Dynamic > Static. Where possible, generate data via APIs or libraries like Faker.
- Think ahead. Build your data strategy with scalability and multi-environment support in mind.

From Chaos to Confidence
Hard-coded test data might seem harmless at first, but it’s one of the most dangerous pitfalls in automation. It leads to brittle scripts, wasted debugging time, and frustrated teams.
By moving to a centralized, dynamic, and scalable test data strategy, we not only stabilized our framework but also gave our team confidence that our tests reflected reality.
For me, this was one of the biggest turning points in my SDET journey. Once we killed hard-coded data, everything else—from regression runs to CI/CD pipelines—became smoother, faster, and more reliable.
If you’re still hardcoding values in your tests, take it from me: kill that habit now. Build a centralized strategy. It’s an investment that pays back every single day, in stability, scalability, and peace of mind.
FAQs
1. What is centralized test data in automation testing?
Centralized test data refers to storing and managing all test input values in a single repository instead of hard-coding them inside scripts. This allows tests to remain stable, reusable, and easier to maintain across environments.
2. Why should we avoid hard-coded test data?
Hard-coded data causes brittle tests, frequent failures, duplication, and difficulty when running tests across multiple environments. Small data changes require editing many scripts, slowing down QA.
3. How does centralized test data improve scalability?
When all test data comes from one source of truth, any change is updated once and automatically used across the entire test suite — making it easy to scale from dozens to thousands of tests.
4. What tools can be used to generate dynamic test data?
API-based data generators and libraries like Faker, Mockaroo, or custom microservices can create unique and realistic data for automation on demand.
5. Can centralized data support multi-environment testing?
Yes. By storing environment-specific values in mapped configuration files (like JSON or YAML), the same tests can run in QA, Preprod, or Prod simply by switching the config reference.
We Also Provide Training In:
- Advanced Selenium Training
- Playwright Training
- Gen AI Training
- AWS Training
- REST API Training
- Full Stack Training
- Appium Training
- DevOps Training
- JMeter Performance Training
Author’s Bio:

Content Writer at Testleaf, specializing in SEO-driven content for test automation, software development, and cybersecurity. I turn complex technical topics into clear, engaging stories that educate, inspire, and drive digital transformation.
Ezhirkadhir Raja
Content Writer – Testleaf
![]()





