As a QA professional with years of experience, I’ve learned the hard way that one of the biggest bottlenecks in test automation is the process of manual test data creation.
It’s a challenge that every tester has faced at some point, but over time, I realized it was more than just a nuisance—it was a barrier that slowed down the entire quality assurance process.
Here’s why manual test data creation is a significant roadblock for QA teams and how automating this process can help your team move from chaos to confidence.
The Old Way: Manual Test Data Creation
In the early stages of my journey as a tester, I remember the sheer number of hours I spent creating test data. It wasn’t just about entering values into fields.
It was about ensuring that each test scenario had the right combinations of input values, edge cases, and expected results.
Here are some of the challenges we faced:
- Time-Consuming
Creating test data manually is incredibly slow. Whether it’s setting up database records, populating forms, or preparing complex data sets for integration testing, the process eats up precious hours. In an agile environment, where quick feedback loops are essential, these delays can make it hard to keep up with fast-paced development cycles. - Human Error
Manually creating test data introduces a high risk of human error. A missing value, incorrect data type, or duplicated record can cause a test to fail for the wrong reasons. These errors can be time-consuming to debug, as it’s not always obvious that the issue lies in the test data itself. - Limited Test Coverage
When test data creation is manual, it’s easy to overlook certain scenarios or edge cases. You might only generate the simplest, most obvious data sets, but you’ll miss the complex ones that could break your system. Without a variety of data combinations, your tests won’t fully simulate real-world conditions, which means defects could slip through undetected. - Scalability Issues
As your test suite grows, the need for data expands too. Manually creating hundreds (or thousands) of unique data sets becomes a daunting task. This lack of scalability often forces teams to either reuse the same data (leading to false positives) or create too many redundant records that clutter the system.

Other Helpful Articles: automation testing interview questions
The Shift: Realizing the Problem
I vividly remember a turning point in my early career as a tester when I realized the scale of the issue. I was manually preparing test data for a large integration test and ran into a problem: the data I had created wasn’t covering all the necessary scenarios. I spent hours revising the data, but as the requirements grew, I simply couldn’t keep up.
That’s when I started to understand the importance of automation not just for the tests themselves, but for the test data generation process too. I knew something had to change if we wanted to achieve faster test cycles and improve the quality of our results.
The Solution: Automating Test Data Creation
After months of struggling with manual data creation, we finally made the decision to automate our test data generation.
This decision revolutionized our approach to testing and brought multiple benefits to the entire QA process.
Here’s what we did to overcome the pain points:
- Using APIs for Data Generation
One of the first things we did was integrate an API for unique ID generation. With an API call, we could generate IDs for tests without worrying about duplicates or overlaps in data. The API would validate the ID and ensure it hadn’t been used before, saving us from spending valuable time manually checking for conflicts.

- Adopting Faker for Randomized Data
To generate realistic yet random test data (such as names, email addresses, phone numbers, etc.), we integrated the Faker library. Faker allows us to create large amounts of data quickly and efficiently. It ensures that our data remains varied and covers a broad spectrum of real-world inputs, from simple fields like names and emails to more complex combinations of value. With Faker, we didn’t need to worry about creating data manually or reusing old data sets. This was a game changer, as it dramatically increased our test coverage without adding complexity. - Centralized Test Data Repository
Another step we took was creating a centralized test data repository that all our tests could pull from. This repository holds all the required test data, making it easier to maintain, update, and reuse. Instead of manually creating the same sets of data for different tests, we now had a single, scalable data set that we could easily adapt for any test scenario. - Parameterized Test Data
We moved to parameterized test cases, where instead of writing multiple similar test scenarios, we passed the test data as parameters. This approach allowed us to reuse the same test scripts with different input data, significantly reducing test creation time while maintaining comprehensive coverage. - Data-Driven Testing Frameworks
By using a data-driven testing framework, we could externalize the test data from the test scripts. This meant our test cases weren’t tied to hardcoded values, and we could easily swap in different data sets as needed. This approach also allowed us to run the same test across multiple scenarios with minimal changes to the script itself.

Don’t Miss Out: playwright interview questions
The Results: Speed, Scalability, and Accuracy
By automating our test data generation process, we saw immediate improvements in several key areas:
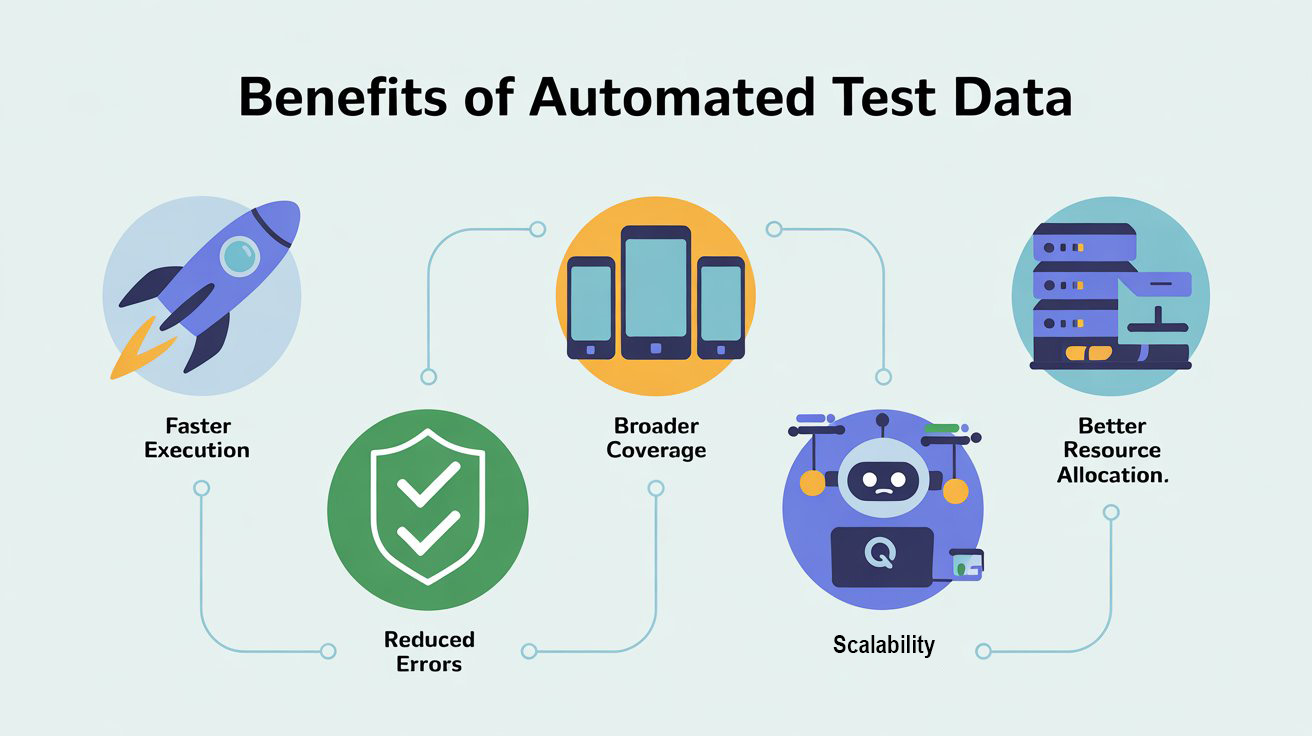
- Faster Test Execution
Automating test data meant we no longer had to manually create data before running tests. Our tests could be executed faster, and our feedback loops became shorter. This was especially critical in an agile environment where speed and adaptability are essential. - Reduced Errors and More Reliable Tests
Automation eliminated the risk of human error in test data creation. With APIs and libraries like Faker, our test data became more reliable, leading to more stable test results and fewer false failures caused by incorrect data.

- Broader Test Coverage
Automated data generation allowed us to easily expand our test coverage. We could now generate varied and complex data sets that covered a broader range of scenarios, including edge cases that we would have previously missed during manual data creation. - Scalability
Our automated test data creation was highly scalable. As our tests grew, we could quickly adapt and generate new sets of data as needed. What was once a time-consuming manual task became a streamlined, automated process that could handle thousands of test cases with ease. - Better Resource Allocation
With the time saved by automating test data creation, our team could focus on more critical tasks—like improving test scripts, analyzing results, and collaborating with developers. Our overall productivity increased, and we saw a significant improvement in team morale.
The Takeaway: Embrace Automation to Overcome Bottlenecks
Manual test data creation is a major bottleneck that can seriously slow down your QA process. In my experience, automating this process with tools like APIs and Faker not only speeds up execution but also makes tests more reliable, accurate, and scalable.
As your testing efforts grow, you’ll find that manual approaches simply can’t keep up. Embrace automation and save yourself (and your team) countless hours of unnecessary work. The transition from chaos to confidence isn’t easy, but when you invest in smarter, more efficient testing processes, you’ll be amazed at how much smoother your entire QA lifecycle can be.
By implementing automated test data creation, we didn’t just improve our processes—we transformed the way we approached testing. And trust me, this shift from manual chaos to automated confidence was one of the best decisions I’ve made in my career as a tester.
FAQs
Q1: Why is manual test data creation a problem in QA?
Manual data creation is slow, error-prone, and hard to scale. It limits test coverage and delays delivery, especially in agile teams that depend on quick feedback loops.
Q2: How can automating test data creation improve QA efficiency?
Automation saves time and reduces human errors. Tools like Faker and APIs help generate unique, dynamic data instantly, improving coverage and stability across test runs.
Q3: What tools are best for automated test data generation?
Popular tools include Faker, Mockaroo, and API-based data generators. These allow testers to create realistic and varied datasets for different environments and scenarios.
Q4: How does a centralized test data repository help QA teams?
A centralized repository ensures data consistency across tests, prevents duplication, and simplifies maintenance. It’s easier to update and reuse data for multiple test cases.
Q5: Can automation fully replace manual test data creation?
While automation handles 90% of cases efficiently, manual input may still be needed for specialized or rare edge cases. The key is to balance both approaches strategically.
We Also Provide Training In:
- Advanced Selenium Training
- Playwright Training
- Gen AI Training
- AWS Training
- REST API Training
- Full Stack Training
- Appium Training
- DevOps Training
- JMeter Performance Training
Author’s Bio:

Content Writer at Testleaf, specializing in SEO-driven content for test automation, software development, and cybersecurity. I turn complex technical topics into clear, engaging stories that educate, inspire, and drive digital transformation.
Ezhirkadhir Raja
Content Writer – Testleaf
![]()