
If you’ve worked in QA long enough, you know that test data can make or break your automation efforts. It sounds simple: just feed your tests some input values and check the output. But in reality, creating and maintaining reliable test data is one of the hardest parts of building stable automation.
When I started my journey as a tester, we relied heavily on manual test data creation. We’d spend hours preparing spreadsheets, crafting sample records, and writing SQL queries just to insert test values into our systems. At first, it felt manageable, but as the number of test cases grew, this approach quickly became a nightmare.
That’s when I discovered how combining APIs and Faker could change everything. Today, I want to share how this shift transformed our workflow, made our test execution 10x faster, and helped us move from chaos to confidence.
The Pain of Manual Test Data
Before automation, test data creation was like cooking without proper ingredients. Here’s what we struggled with:
- Duplication & Conflicts: We often ended up reusing the same IDs or account numbers, which caused test failures that had nothing to do with bugs in the product.
- Time Sink: Preparing data manually for every regression cycle could take hours—sometimes days.
- Inconsistent Data: One tester might create data in one format, while another would follow a different convention. This inconsistency led to unreliable test outcomes.
- Limited Coverage: Since manual creation took so long, we only tested the “happy path.” Edge cases were often ignored.
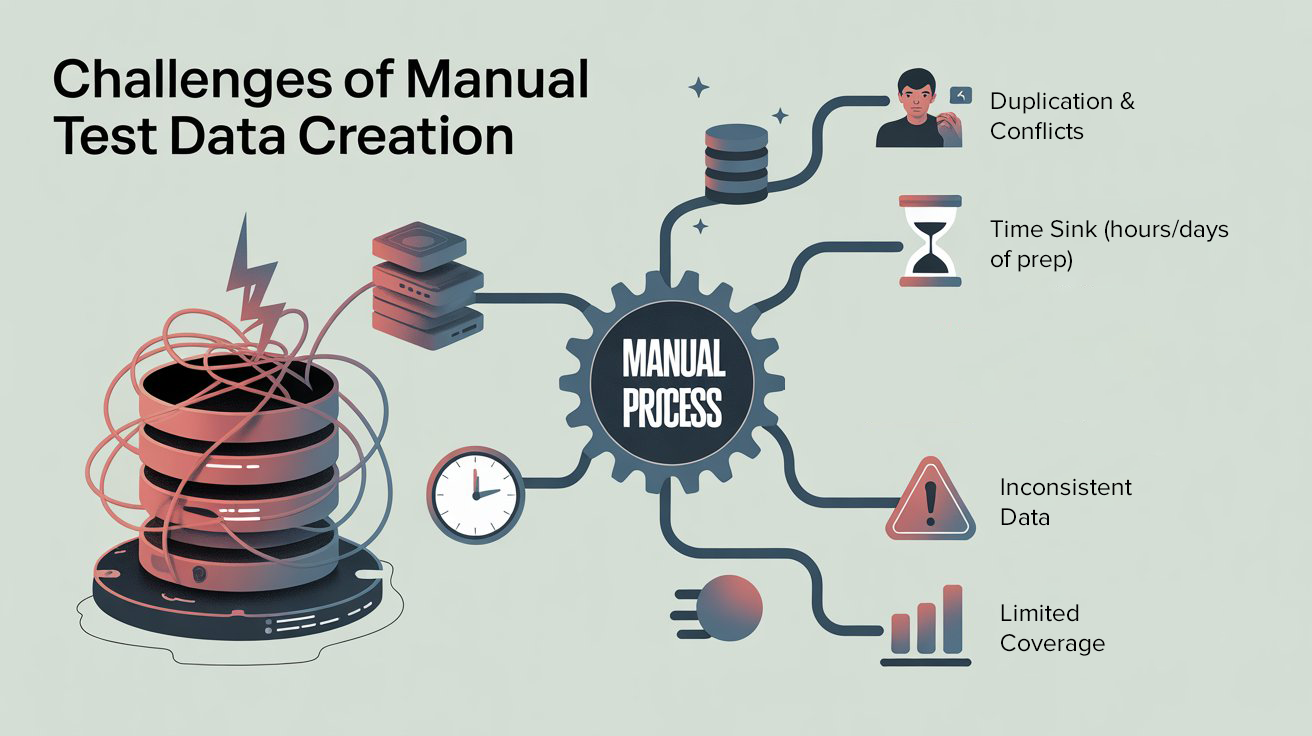
The result? Slower test cycles, false failures, and a QA team constantly firefighting instead of innovating.
Other Helpful Articles: automation testing interview questions
The Turning Point: Why We Needed a Better Approach
The breaking point for me came during a release cycle where half of our test cases failed—not because of product bugs, but because of bad test data. IDs were clashing, emails were duplicated, and some records simply weren’t inserted properly into the database.
I realized that if we didn’t fix our test data strategy, our automation framework would never achieve stability. That’s when we started experimenting with automation-first test data generation.
Step 1: APIs for Unique IDs
One of the biggest issues we faced was generating unique identifiers like account numbers or customer IDs. When done manually, we’d either pick random numbers (and risk duplication) or use incremental IDs (which weren’t always valid in production-like systems).
To solve this, we built an internal API service that could generate unique IDs on demand. This service would:
- Generate a random ID following the correct format.
- Validate it against existing records.
- Return the ID only if it was truly unique.
This simple API call eliminated duplicate ID failures almost overnight. Instead of spending time verifying uniqueness manually, our test scripts could now just hit the API and instantly get a usable ID.

Step 2: Faker for Realistic Test Data
Unique IDs solved part of the problem, but what about names, emails, phone numbers, and addresses? That’s where Faker came in.
For those unfamiliar, Faker is a library that generates fake yet realistic data. With just a few lines of code, we could generate:
- Random names that look real (e.g., “John Smith”, “Priya Nair”)
- Valid email addresses that wouldn’t clash (“alex.jones@testmail.com”)
- Random phone numbers, addresses, and even financial data
- Locale-specific data (e.g., different formats for U.S., U.K., or India)
The beauty of Faker was its flexibility. We could configure it to mimic real-world scenarios:
- Emails with corporate domains for B2B testing
- Addresses spread across different regions for compliance tests
- Phone numbers that matched regional formats
Suddenly, our test data wasn’t just faster—it was more diverse and realistic, which improved coverage dramatically.
Step 3: Centralized Test Data Service
With APIs handling IDs and Faker generating dynamic data, we took things a step further: we built a centralized test data service.
Instead of each tester creating their own scripts, we exposed common endpoints like:
- /generate/customer → Returns a ready-to-use customer profile (ID, name, email, phone)
- /generate/account → Returns a valid bank account with balance and transaction history
- /generate/order → Returns a sample order with unique identifiers
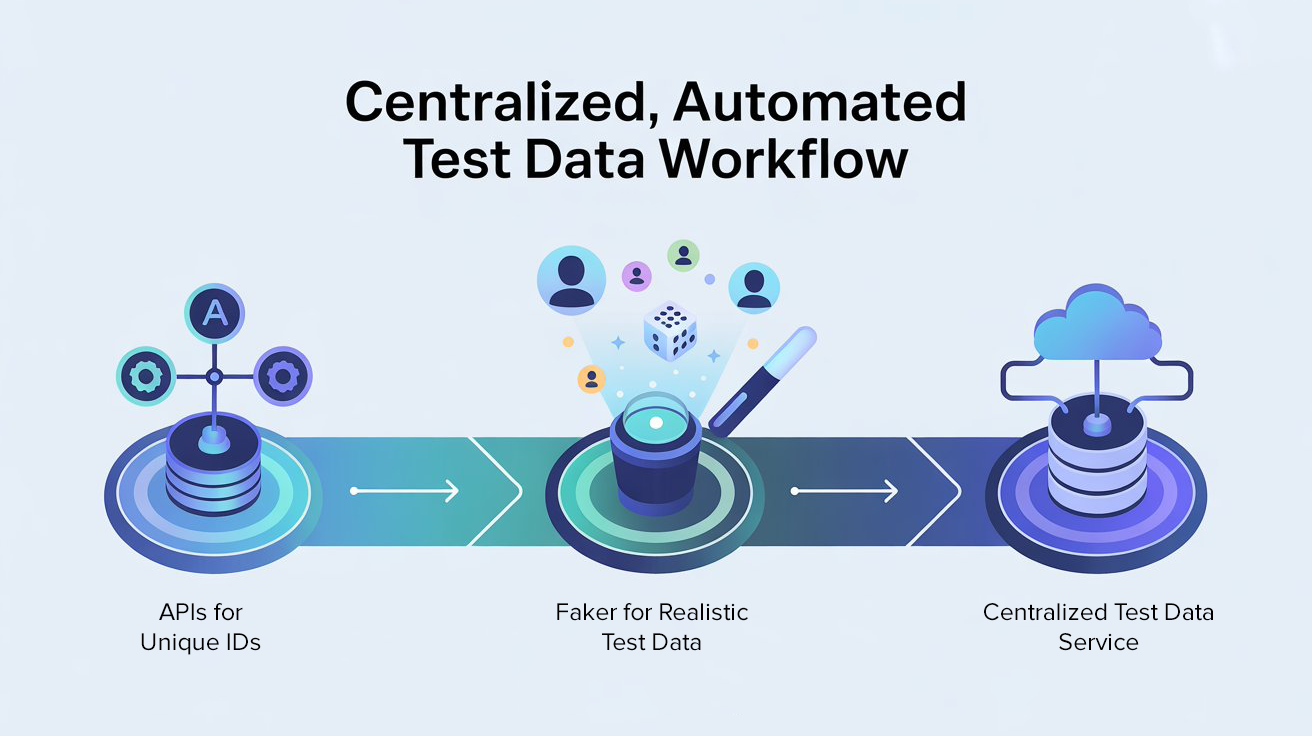
Now, every test script across the team could pull from the same standardized, reusable data service. This eliminated inconsistencies and reduced the time to set up new tests.
Recommended for You: Epam interview question
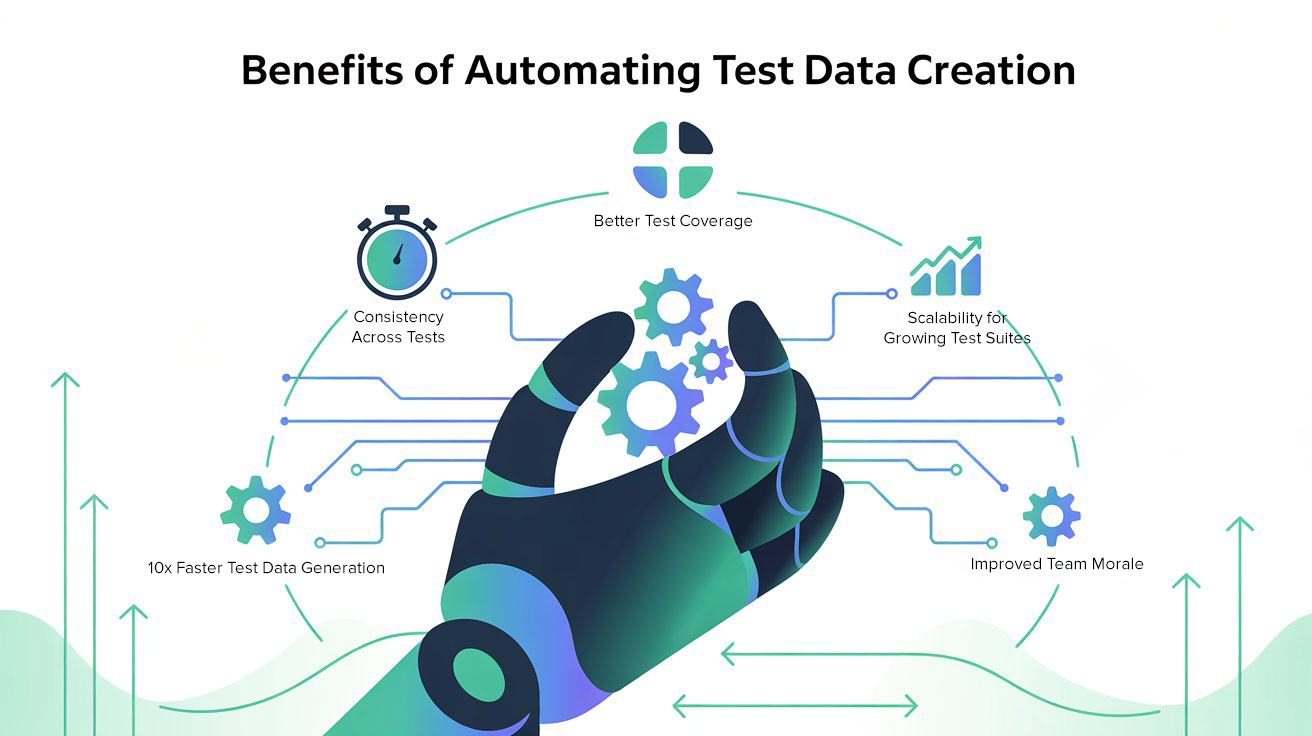
The Results: 10x Faster and Far More Reliable
The impact of this shift was immediate and measurable:
- Time Savings
What used to take hours of manual prep now happened in seconds. A single API call could generate a complete, valid test record. We estimated that test data setup time dropped by 90%.
- Consistency Across Tests
Because all data came from the same service, we eliminated mismatched formats and clashing IDs. Our automation became more stable, with fewer false failures.

- Better Test Coverage
Since data was easy to generate, we finally had the bandwidth to test edge cases—like invalid inputs, boundary values, and large datasets.
- Scalability
When our regression suite grew from dozens to hundreds of test cases, test data generation didn’t slow us down. APIs and Faker scaled effortlessly with our needs.
- Team Morale
This was an underrated benefit. Testers no longer dreaded “data prep day.” Instead, they focused on writing smarter tests and analyzing failures. The team felt more productive and valued.
Lessons Learned Along the Way
Looking back, a few key lessons stand out from this transformation:
- Test data is as important as the test scripts. You can’t achieve automation stability without a reliable data strategy.
- APIs and Faker complement each other. APIs ensured uniqueness and validity, while Faker brought diversity and realism.
- Centralization avoids duplication of effort. A single shared data service made collaboration easier and improved maintainability.
- Automation is about removing bottlenecks. Manual data creation was our biggest bottleneck, and once we automated it, everything else became easier.
Don’t Miss Out: api automation interview questions
From Chaos to Confidence
For me, this was one of the first big wins as a tester moving into the SDET role. What started as a chaotic, time-consuming struggle with manual data creation turned into a fast, reliable, and scalable system.
By combining APIs for unique IDs and Faker for realistic data, we didn’t just speed things up—we built confidence in our automation framework. Our tests were finally trustworthy, and our QA team could keep pace with the rapid release cycles of modern development.
If your team is still stuck in the manual data trap, my advice is simple: start small, automate test data, and watch how quickly your testing speed and quality improve.
This early lesson—transforming chaos into confidence—set the stage for everything else I went on to build as an SDET.
FAQs
Q1. Why is manual test data creation inefficient in QA?
Manual test data creation is slow, inconsistent, and prone to duplication errors—leading to flaky tests and unreliable results. Automating test data ensures speed and accuracy.
Q2. How does Faker help in generating test data?
Faker generates realistic names, emails, phone numbers, addresses, and localized data. This improves data diversity and helps simulate real-world usage in test scenarios.
Q3. Why use APIs for unique ID generation in test automation?
APIs can ensure IDs follow business rules and are unique by validating them against existing records. This prevents test failures caused by data collisions.
Q4. What is a centralized test data service?
A centralized service exposes endpoints to generate full test-ready profiles (e.g., customer, order, account). It ensures reusable, consistent data across test suites and teams.
Q5. How does automated test data creation improve test coverage?
Because data can be generated instantly, QA teams finally have time to test boundary conditions, negative scenarios, and edge cases—leading to stronger product quality.
We Also Provide Training In:
- Advanced Selenium Training
- Playwright Training
- Gen AI Training
- AWS Training
- REST API Training
- Full Stack Training
- Appium Training
- DevOps Training
- JMeter Performance Training
Author’s Bio:

Content Writer at Testleaf, specializing in SEO-driven content for test automation, software development, and cybersecurity. I turn complex technical topics into clear, engaging stories that educate, inspire, and drive digital transformation.
Ezhirkadhir Raja
Content Writer – Testleaf
![]()
