
Most Selenium suites do not become painful because teams wrote too many tests.
They become painful because the execution model never matured.
A suite that works for 50 tests can collapse under 500. What once felt acceptable as a local automation effort becomes a CI/CD bottleneck: builds slow down, reruns increase, flaky failures spread, and trust in the pipeline starts to erode. Selenium is not usually the real problem. More often, the problem is that teams are still treating browser automation like a collection of scripts instead of a delivery system.
That shift in mindset matters.
Because once UI automation becomes part of release governance, the question is no longer, “Does the script pass?” The real questions become: How quickly does the suite return a trustworthy signal? How efficiently does it use infrastructure? How often do unstable tests waste developer time? And can the pipeline remain credible as the suite grows? Those are engineering questions, not just testing questions.
What is Selenium at scale?
Selenium at scale refers to running large automation suites efficiently using parallel execution, smart sharding, and flaky test management to ensure fast and reliable CI pipelines.
In This Guide You’ll Learn:
- Why parallelism alone is not enough
- How smart sharding improves CI efficiency
- Why flaky tests reduce trust
- How quarantine improves pipeline reliability
Speed is not a luxury in CI/CD
In modern delivery pipelines, delayed feedback is expensive. As suites become larger, every extra minute in CI affects developers, reviewers, release schedules, and confidence in the build itself.
So yes, parallelism matters. But parallelism alone is not maturity.
Parallelism does not fix bad automation. It exposes it faster.
Parallelism reveals whether your tests were isolated in the first place
The business case for parallel execution is easy to understand. If you can run ten tests at once instead of one after another, total feedback time falls dramatically.
But here is where many teams get it wrong: they treat parallelism as an infrastructure upgrade when it is actually an architecture test.
The moment you increase concurrency, hidden weaknesses surface:
- Shared test accounts start colliding
- Static test data gets corrupted
- Order-dependent scenarios begin to fail
- Cleanup routines that “mostly worked” are no longer enough
- Environment assumptions become painfully visible
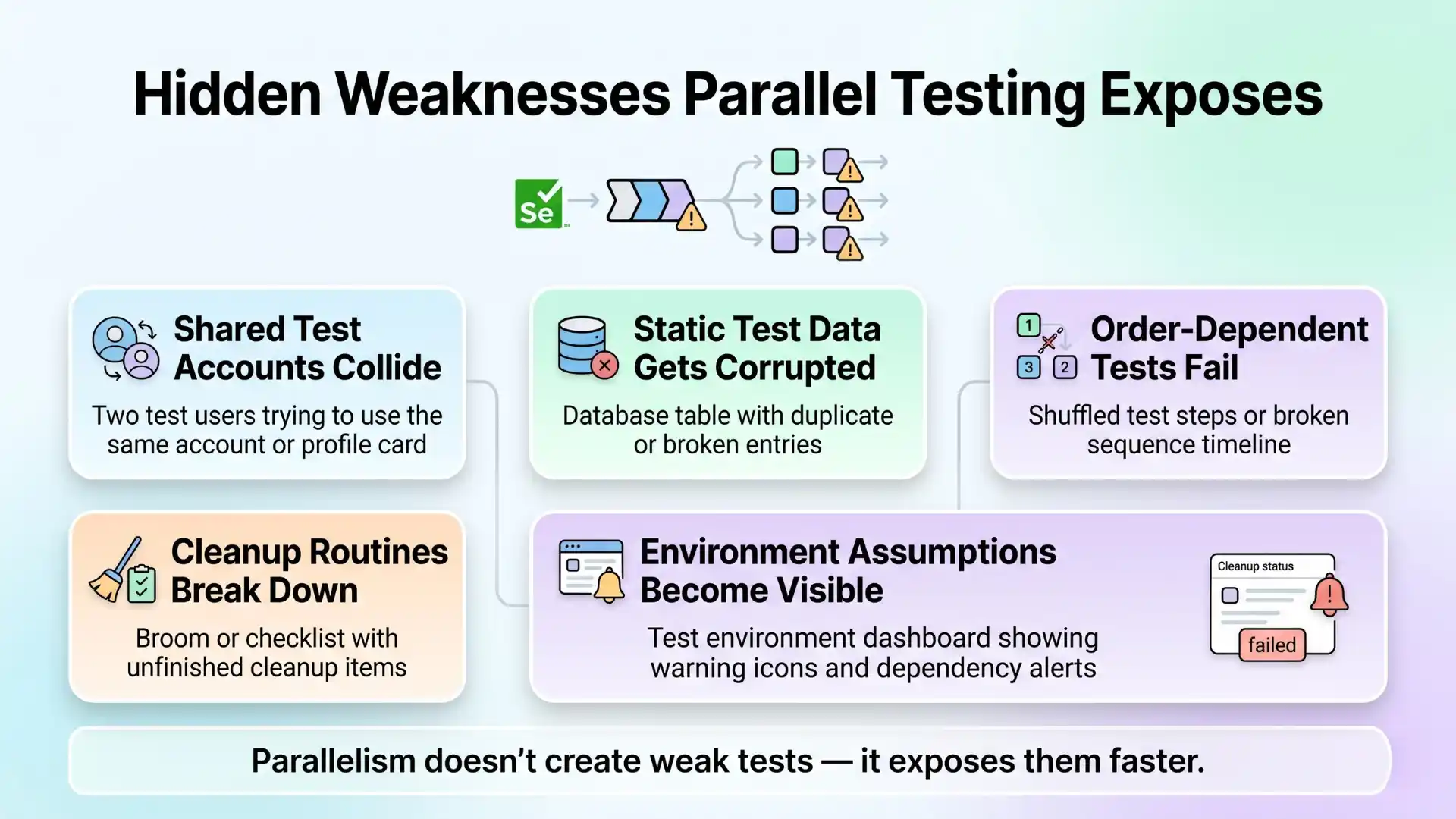
In other words, a suite that appears stable in sequential mode may only be stable because it has been protected from reality.
This is why the first principle of scalable Selenium is not “add more nodes.” It is improve isolation.
Every test that runs in parallel should behave as though it owns its own world: its own data setup, its own teardown, and its own state boundaries. The faster you want the suite to run, the more disciplined your test design must become.
Smart sharding matters more than most teams realize
Parallelism answers one question: how many tests can run at the same time?
Sharding answers another: how should the suite be divided so the pipeline finishes efficiently?
This is where many CI pipelines waste money and time. Teams split tests across agents, but without a real strategy. One shard finishes in five minutes. Another takes thirty. The pipeline still waits for the slowest group. On paper, the suite is “parallelized.” In practice, it is still bottlenecked.
The goal of sharding is not simply distribution. It is balanced distribution.
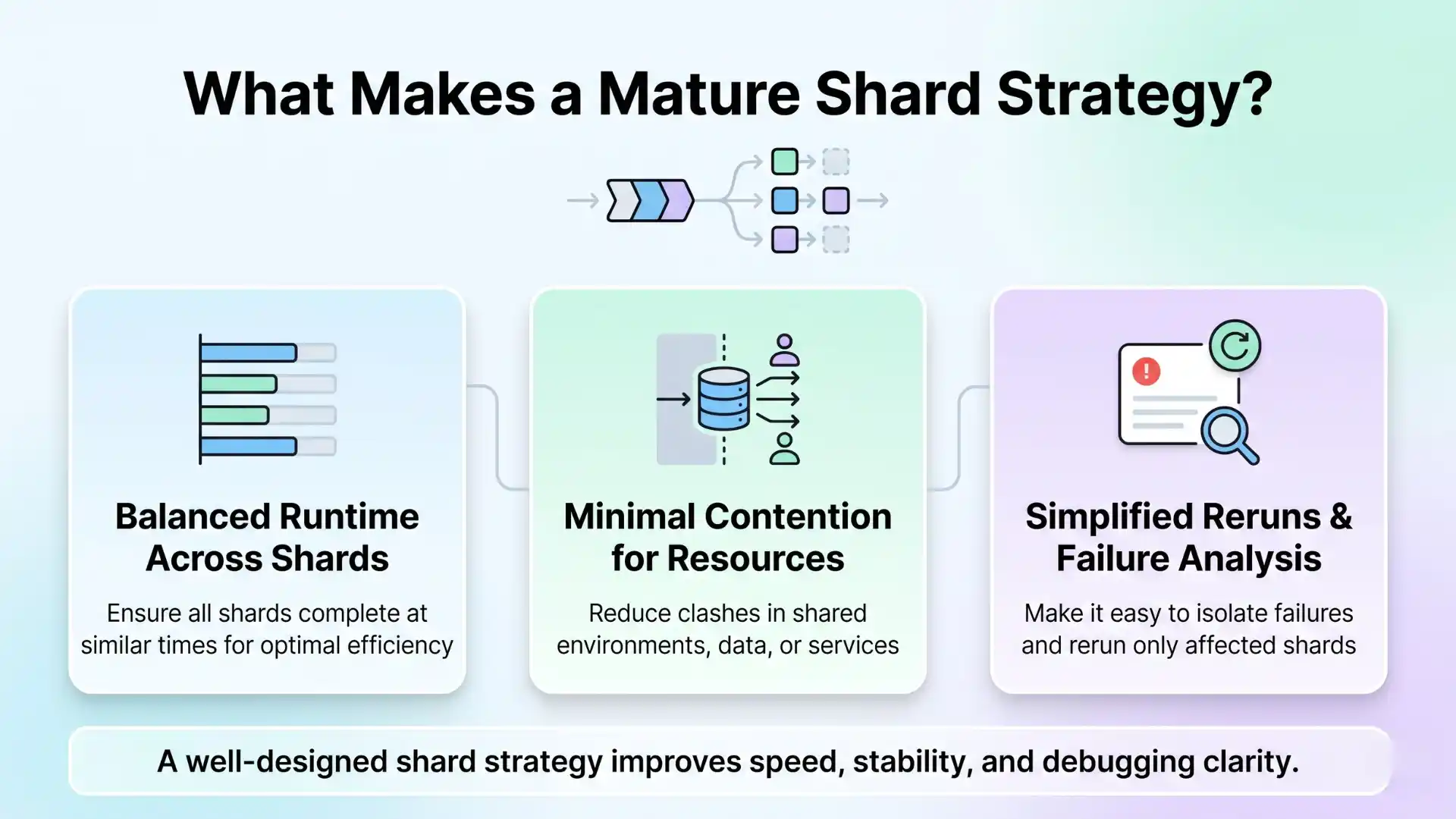
A mature shard strategy should do three things well:
- Keep runtime roughly even across shards
- Minimize contention for shared environments or data
- Make reruns and failure analysis easier
Static folder-based sharding is easy to start with. It is also easy to outgrow. Large suites evolve unevenly. A login module may stay small while checkout, reporting, or admin flows become much heavier. Over time, static shards drift out of balance.
That is why duration-aware sharding is usually the better long-term approach. If you use historical runtime data to distribute long, medium, and short tests intelligently, overall pipeline time becomes far more predictable. This is not just an optimization tactic. It is a reliability tactic. Predictable runtime improves planning, budgeting, and developer trust.
At Testleaf, this is one of the most important lessons teams miss: scaling Selenium is not only about concurrency; it is about execution economics. The pipeline should not merely run faster. It should run faster in a controlled, observable, repeatable way.
Flaky tests are not only a technical issue. They are a trust issue.
A flaky test is dangerous not because it fails once. It is dangerous because it weakens the meaning of failure itself.
For browser-heavy automation, the risk is not just instability. It is the erosion of team behavior.
When failures become noisy:
- Developers rerun jobs instead of trusting the first signal
- Real regressions hide inside inconsistent failure patterns
- Release decisions slow down
- Teams normalize red builds
- Ownership gets blurred because nobody believes the result strongly enough to act immediately
That is why flaky tests should be treated as trust debt.

Quarantine is not surrender. It is governance.
Many teams resist quarantining flaky tests because they think it means lowering standards.
The opposite is true.
A disciplined quarantine process is a sign that the team understands the difference between preserving pipeline trust and pretending a known problem does not exist. If a test is unstable enough to repeatedly block unrelated merges, it should not continue to poison the main CI signal.
Quarantine done well means:
- The test is clearly labeled
- It is removed from merge-blocking status checks
- It still runs in a separate reporting lane
- It is visible to the team
- It has an owner
- It has a review SLA
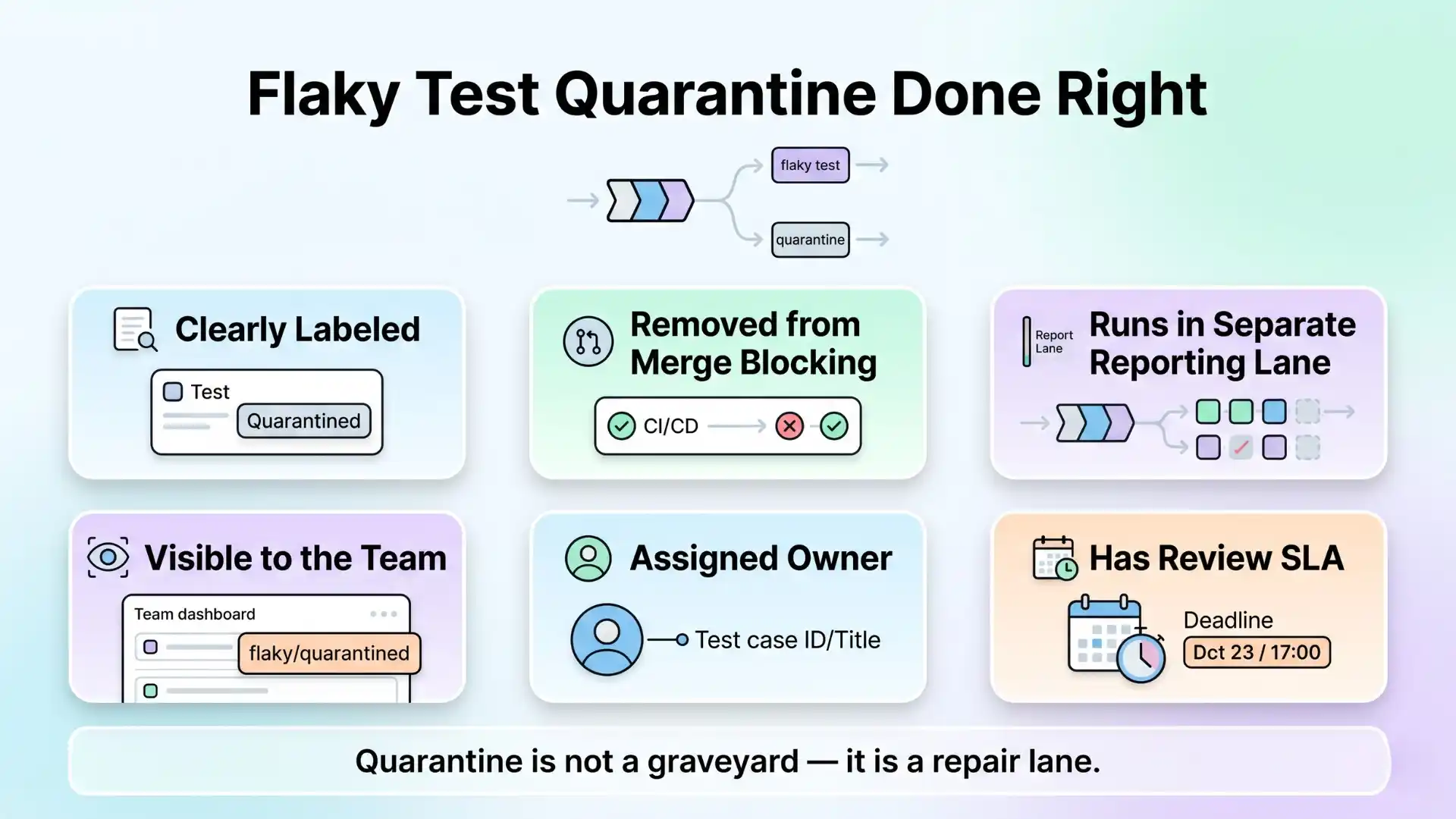
Without those rules, quarantine becomes a graveyard. With those rules, it becomes a repair lane.
This is where mature QA governance begins. Not at the level of locators or page objects, but at the level of policy. Which failures should block a release? Which tests are trusted enough to gate merges? How often is flake debt reviewed? What is the acceptable retry policy? These are the questions that separate automation activity from automation leadership.
What strong Selenium teams do differently
The highest-value Selenium teams usually share a few habits:
They design tests for isolation before scaling them.
They use parallelism deliberately, not as a reflex.
They rebalance shards based on observed runtime, not guesswork.
They measure flake rate, rerun rate, shard runtime, and quarantine count.
And they understand a simple truth: a test suite is only useful if the organization trusts the signal it produces.
That is the heart of this discussion.
Not more tests.
Not more threads.
Not more agents.
Better signal.
Key Takeaways
- Parallelism exposes weak test design
- Smart sharding reduces pipeline bottlenecks
- Flaky tests are a trust issue, not just technical
- Quarantine improves signal reliability
Conclusion
As Selenium suites grow, the challenge is no longer just automation coverage. It is execution strategy.
Parallelism reduces feedback time. Smart sharding prevents infrastructure waste. Flaky quarantine protects the credibility of the main pipeline. Together, these practices turn Selenium from a slow operational burden into a dependable delivery signal.
The real maturity test is not whether your Selenium suite can run.
It is whether your team can still trust it when the suite becomes large, fast, and business-critical.
FAQs
What is Selenium at scale?
Selenium at scale refers to running large automation test suites efficiently using parallel execution, smart sharding strategies, and flaky test management to ensure fast and reliable CI/CD pipelines.
Why is parallel execution important in Selenium?
Parallel execution reduces test execution time by running multiple tests simultaneously, helping teams get faster feedback in CI/CD pipelines and improve release speed.
Does parallelism alone solve test execution problems?
No. Parallelism exposes issues like shared data conflicts, poor test isolation, and unstable environments, but it does not fix them without proper test design.
What is test sharding in Selenium?
Test sharding is the process of splitting test suites into smaller groups and distributing them across multiple machines or nodes to improve execution efficiency and reduce pipeline time.
What makes a good sharding strategy?
A good sharding strategy balances execution time across shards, reduces resource contention, and makes reruns and failure analysis easier using runtime-based distribution.
What are flaky tests in automation testing?
Flaky tests are tests that fail inconsistently without changes in the code, often due to timing issues, environment instability, or poor test design.
Why are flaky tests a serious problem in CI/CD?
Flaky tests reduce trust in the test pipeline, cause unnecessary reruns, hide real defects, and slow down release decisions.
What is flaky test quarantine?
Flaky test quarantine is the practice of isolating unstable tests from merge-blocking pipelines while still tracking and fixing them in a separate reporting flow.
How does quarantine improve test reliability?
Quarantine prevents unstable tests from affecting CI results, ensuring that only reliable tests influence release decisions while flaky tests are fixed separately.
What is the key to scaling Selenium successfully?
The key is combining parallel execution, smart sharding, strong test isolation, and disciplined flaky test management to maintain fast and trustworthy pipelines.
We Also Provide Training In:
- Advanced Selenium Training
- Playwright Training
- Gen AI Training
- AWS Training
- REST API Training
- Full Stack Training
- Appium Training
- DevOps Training
- JMeter Performance Training
Author’s Bio:

Content Writer at Testleaf, specializing in SEO-driven content for test automation, software development, and cybersecurity. I turn complex technical topics into clear, engaging stories that educate, inspire, and drive digital transformation.
Ezhirkadhir Raja
Content Writer – Testleaf
![]()





