
Data preprocessing in machine learning is the process of cleaning, transforming, encoding, scaling, and organizing raw data before it is used to train a machine learning model. It helps improve model accuracy, reduce errors, prevent data leakage, and make machine learning systems more reliable in real-world use.
Machine learning models do not perform well just because the algorithm is powerful. They perform well when the data is clean, consistent, relevant, and ready for training. This is why data preprocessing is one of the most important steps in the machine learning lifecycle.
Raw data usually contains missing values, duplicate records, inconsistent formats, outliers, text categories, different measurement scales, and unwanted noise. If this data is directly given to a model, the model may learn wrong patterns or produce poor predictions.
Why Data Preprocessing Matters
Data preprocessing matters because machine learning models depend heavily on the quality of input data. Even a good algorithm can fail if the data is incomplete, biased, inconsistent, or poorly structured.
For example, imagine a customer churn prediction model. If customer age has missing values, income is stored in different formats, and location data is written inconsistently, the model will struggle to find meaningful patterns. After preprocessing, the same data becomes cleaner, more consistent, and more useful for prediction.
Key Benefits of Data Preprocessing
- Improves machine learning model accuracy
- Reduces errors caused by poor-quality data
- Handles missing, duplicate, and inconsistent values
- Converts raw data into a format models can understand
- Prevents data leakage during model training
- Improves reliability in real-world predictions
- Makes machine learning workflows easier to maintain
Other Helpful Articles: manual testing interview questions
Main Steps in Data Preprocessing
The data preprocessing process usually includes data cleaning, missing value handling, categorical encoding, feature scaling, train-test splitting, and leakage prevention. Each step plays a different role in preparing raw data for machine learning.
| Data Preprocessing Step | Purpose | Example |
| Data Cleaning | Removes errors, duplicates, and inconsistent values | Fixing “Chennai,” “chennai,” and “CHN” into one format |
| Missing Value Handling | Fills or removes empty values | Replacing missing age with median age |
| Categorical Encoding | Converts text values into numbers | Changing “Yes” and “No” into numerical values |
| Feature Scaling | Brings values into a similar range | Scaling salary and age before training |
| Outlier Handling | Detects unusual values | Reviewing extremely high transaction amounts |
| Train-Test Split | Separates training and testing data | Using 80% data for training and 20% for testing |
| Data Leakage Prevention | Avoids test data influencing training | Fitting scalers only on training data |
Data Cleaning in Machine Learning
Data cleaning is the first and most important preprocessing step. It focuses on improving the quality of the dataset before transformation or model training.
Common data cleaning activities include:
- Removing duplicate records
- Correcting spelling or formatting errors
- Fixing inconsistent date formats
- Standardizing category names
- Removing irrelevant columns
- Handling invalid or impossible values
- Checking whether data types are correct
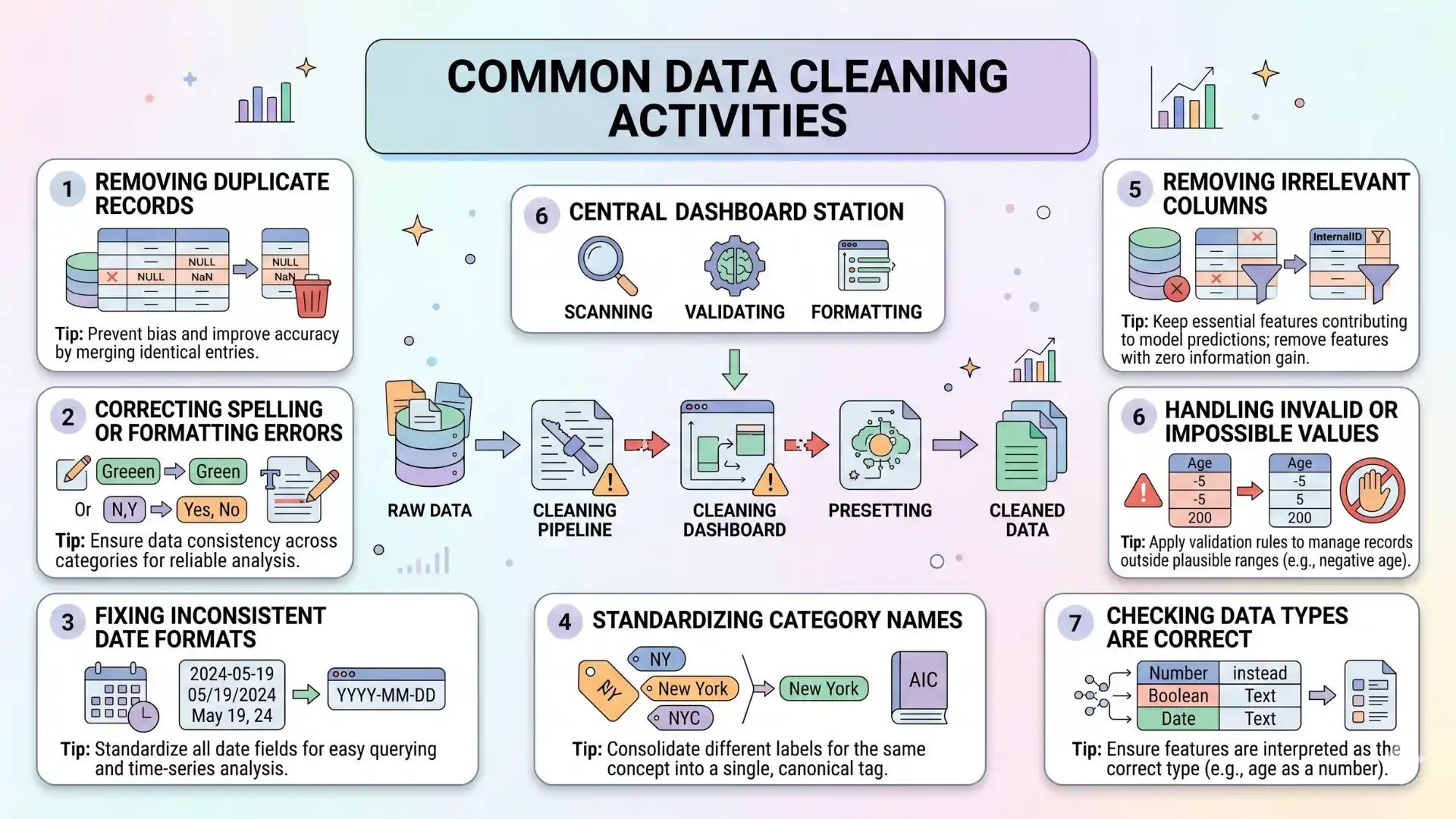
For example, if a dataset contains location values like “Chennai,” “CHN,” and “chennai,” the model may treat them as separate locations. Data cleaning solves this by standardizing them into one consistent value.
Handling Missing Values
Missing values are common in real-world datasets. They may occur because users skipped form fields, systems failed to capture data, or records were collected from multiple sources.
There are different ways to handle missing values:
- Remove rows with missing values when the missing data is very small
- Fill numerical values using mean or median
- Fill categorical values using mode
- Use a separate “Unknown” category when the missing value has meaning
- Use advanced imputation methods for complex datasets
The right approach depends on the business context. For example, removing missing medical records may not be safe, but filling a missing product category with “Unknown” may be acceptable.
Explore More: Product based companies in chennai
Categorical Encoding
Machine learning algorithms usually work with numbers, not text. That is why categorical values must be converted into numerical form.
For example:
- “Yes” and “No” can become 1 and 0
- “Low,” “Medium,” and “High” can be encoded in order
- City names or product categories can be converted using one-hot encoding
Categorical encoding is important because incorrect encoding can confuse the model. For example, giving numbers like 1, 2, and 3 to city names may create a false order where no real order exists.
Feature Scaling
Feature scaling is used to bring numerical values into a similar range. This is important for algorithms that depend on distance, gradients, or numerical magnitude.
For example, age may range from 18 to 70, while salary may range from 20,000 to 2,00,000. Without scaling, the model may give more importance to salary simply because the numbers are larger.
Common feature scaling techniques include:
- Normalization: Converts values into a fixed range, usually 0 to 1
- Standardization: Centers values around the mean with standard deviation
- Robust scaling: Useful when the dataset contains outliers
Data Leakage: The Mistake Many Beginners Miss
One of the biggest mistakes in machine learning preprocessing is data leakage. Data leakage happens when information from the test data accidentally influences the training process.
This can make the model look highly accurate during development but fail badly in real-world use.
Common Data Leakage Mistakes
- Scaling the full dataset before train-test split
- Filling missing values using the entire dataset
- Selecting features after looking at test data
- Using future information in prediction problems
- Applying preprocessing differently during training and production
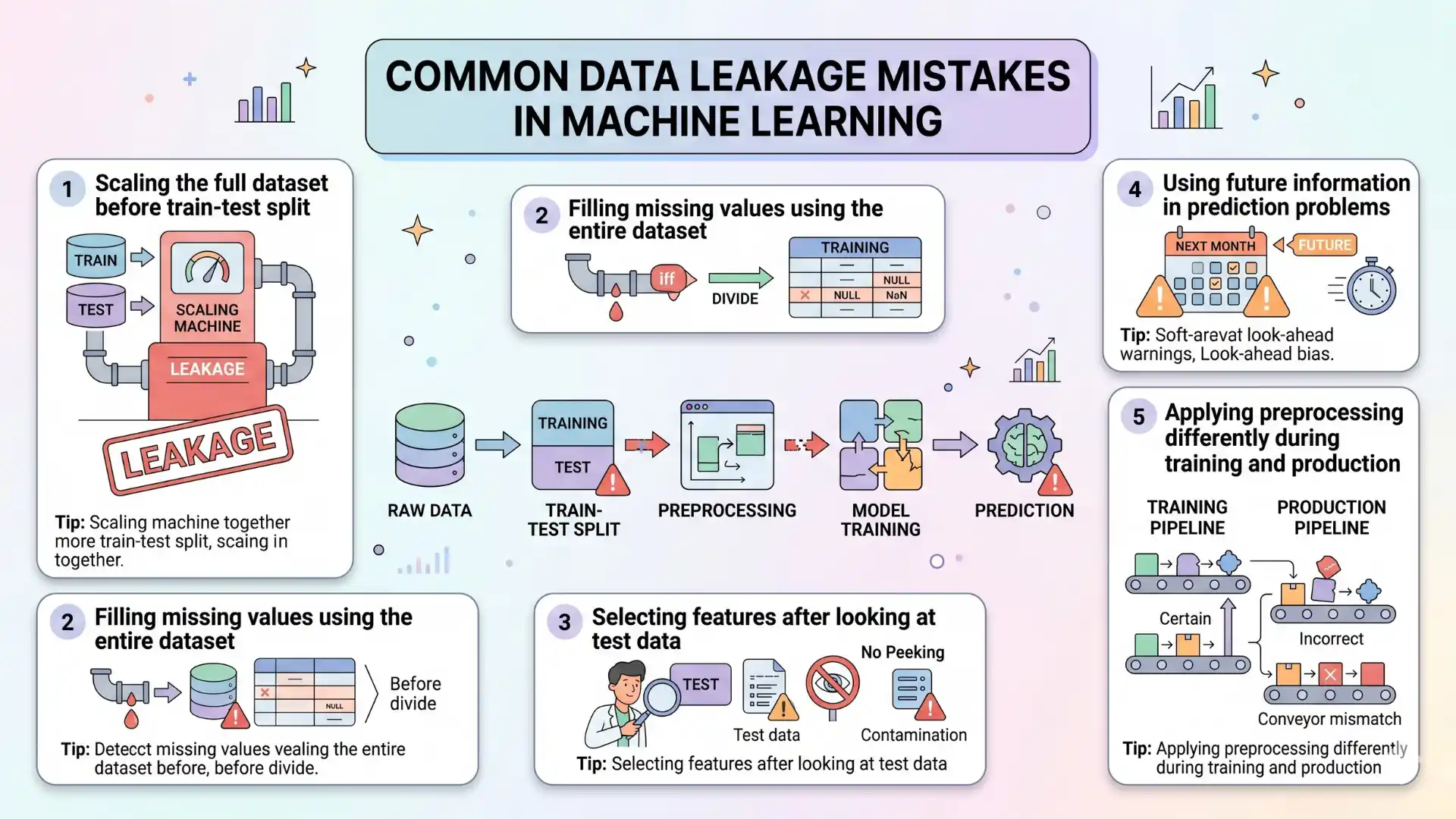
To avoid data leakage, preprocessing should be fitted only on the training data and then applied to the test data. This gives a more realistic measure of model performance.
Other Recommended Reads: Automation testing interview questions
Python Data Preprocessing Workflow
In real-world Python projects, preprocessing is usually done using pandas and scikit-learn. Pandas helps with data inspection, cleaning, filtering, and formatting. Scikit-learn helps with imputation, scaling, encoding, pipelines, and model training.
A strong Python data preprocessing workflow should include:
- Identify numerical and categorical columns
- Clean duplicate and inconsistent records
- Handle missing values separately for each column type
- Encode categorical variables correctly
- Scale numerical features when needed
- Split data into training and testing sets
- Use pipelines to keep preprocessing consistent
This workflow is more reliable than manually applying random transformations to the dataset.
Common Data Preprocessing Mistakes
Many beginners clean the entire dataset before splitting it. This can cause data leakage. Some remove too many rows with missing values and lose important information. Others encode categories incorrectly or apply scaling where it is not needed.
Mistakes to Avoid
- Removing all rows with missing values without analysis
- Ignoring duplicate records
- Treating every outlier as an error
- Using the wrong encoding method
- Forgetting to scale features for distance-based models
- Applying different preprocessing steps in training and production
- Not documenting preprocessing decisions
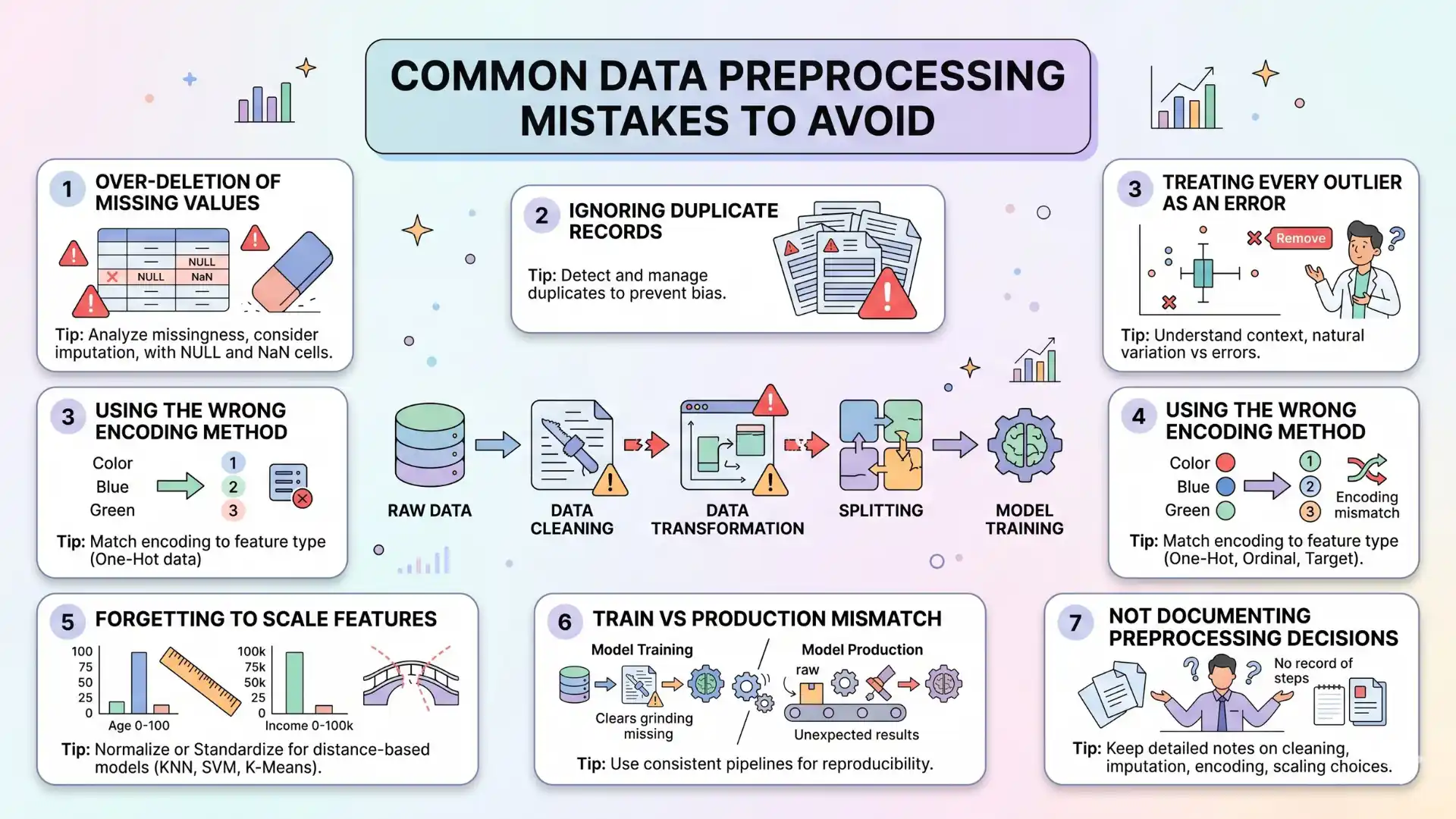
Outliers also need careful handling. Not every outlier is bad. Some outliers represent real business cases, such as high-value customers, rare medical cases, or unusual fraud patterns.
Data preprocessing in machine learning prepares raw data for model training by cleaning missing values, removing duplicates, handling outliers, encoding categorical variables, scaling numerical features, splitting datasets, and preventing data leakage. A strong preprocessing workflow improves model accuracy, reliability, and real-world performance. Modern Python workflows use pandas, scikit-learn preprocessing, Pipeline, and ColumnTransformer to build consistent and reusable machine learning systems.
Conclusion
Data preprocessing is not a small technical step before machine learning. It is the foundation of model quality. Clean data helps models learn better, avoid misleading patterns, and perform more reliably after deployment.
A well-preprocessed dataset can often improve results more than changing the algorithm itself. If you want accurate machine learning models, focus first on preparing your data correctly. Good data preprocessing turns raw information into reliable input, and reliable input is what creates better machine learning outcomes.
FAQs
What is data preprocessing in machine learning?
Data preprocessing in machine learning is the process of cleaning, transforming, encoding, scaling, and preparing raw data before training a model. It helps machine learning algorithms understand the data better and improves model accuracy, consistency, and reliability.
Why is data preprocessing important in machine learning?
Data preprocessing is important because raw data often contains missing values, duplicate records, inconsistent formats, outliers, and incorrect data types. Without preprocessing, machine learning models may learn wrong patterns and produce inaccurate predictions.
What are the main steps in data preprocessing?
The main steps in data preprocessing include data cleaning, handling missing values, removing duplicates, encoding categorical variables, feature scaling, outlier handling, train-test splitting, and preventing data leakage.
What is data cleaning in machine learning?
Data cleaning is the process of fixing errors in a dataset before model training. It includes removing duplicate records, correcting spelling or formatting errors, fixing inconsistent date formats, standardizing category names, and handling invalid values.
How do you handle missing values in machine learning?
Missing values can be handled by removing rows, filling numerical values with mean or median, filling categorical values with mode, using an “Unknown” category, or applying advanced imputation techniques based on the dataset and business problem.
What is feature scaling in data preprocessing?
Feature scaling is the process of bringing numerical values into a similar range. It is useful for machine learning algorithms that depend on distance or gradients, such as KNN, logistic regression, linear regression, and support vector machines.
What is data leakage in machine learning preprocessing?
Data leakage happens when information from test data accidentally influences the training process. This can make a model look accurate during development but perform poorly in real-world predictions.
Should preprocessing happen before or after train-test split?
Train-test split should happen before fitting preprocessing steps. Preprocessing methods like scaling, imputation, and encoding should be fitted only on training data and then applied to test data to avoid data leakage.
What are common data preprocessing mistakes to avoid?
Common mistakes include removing all missing values without analysis, ignoring duplicates, treating every outlier as an error, using the wrong encoding method, skipping feature scaling, applying different preprocessing in training and production, and not documenting preprocessing decisions.
How does data preprocessing improve model accuracy?
Data preprocessing improves model accuracy by giving the algorithm clean, consistent, and meaningful input. When missing values, duplicates, outliers, scaling issues, and categorical variables are handled properly, the model can learn better patterns from the data.
We Also Provide Training In:
- Advanced Selenium Training
- Playwright Training
- Gen AI Training
- AWS Training
- REST API Training
- Full Stack Training
- Appium Training
- DevOps Training
- JMeter Performance Training
Author’s Bio:

Content Writer at Testleaf, specializing in SEO-driven content for test automation, software development, and cybersecurity. I turn complex technical topics into clear, engaging stories that educate, inspire, and drive digital transformation.
Ezhirkadhir Raja
Content Writer – Testleaf
![]()





