
Machine learning content online usually falls into two buckets: short lists that feel like trivia, or long encyclopedias that don’t help you decide. In 2026, the real skill isn’t memorizing model names—it’s choosing the right learning setup, selecting a baseline, and validating results so your system stays reliable when data shifts.
Machine learning is software that learns patterns from examples instead of fixed rules. In 2026, the key skill is choosing the right learning setup, starting with a strong baseline, and validating results so performance stays reliable when data shifts. This guide maps the most-used algorithms to real use cases with a repeatable workflow.
This blog is a practical reference you can reuse. It explains what ML is, clarifies how models learn, and maps common approaches to real use cases—without drowning you in math.
Key Takeaways
- Start with a baseline (often linear), then upgrade only if it proves ROI.
- Prevent leakage with clean splits; it beats “fancier models.”
- The best model in 2026 is the simplest one that meets the metric and stays reliable after deployment.
Machine learning meaning
Machine learning meaning, in plain language, is building software that learns patterns from examples rather than being hand-coded with rules for every scenario. You train a machine learning model on historical data, then use it to make predictions on new data. The “learning” part changes how you debug: when performance drops, the cause is often the data pipeline, labels, objectives, or drift—not a broken if-statement.
A helpful mindset: treat ML as an engineering system. Your model is only one component; evaluation, monitoring, and retraining are equally important.
Types of learning in machine learning
Most real projects fit into four learning styles:
- Machine learning supervised learning: you have inputs and correct outputs (labels). This is where supervised learning algorithms shine, especially for classification and regression.
- Unsupervised learning: no labels; the goal is to discover structure such as clusters or low-dimensional representations.
- Reinforcement learning: the system learns by acting and receiving rewards; useful when actions influence future states.
- Self-/semi-supervised learning: learn representations from large unlabeled data, then adapt using limited labels.
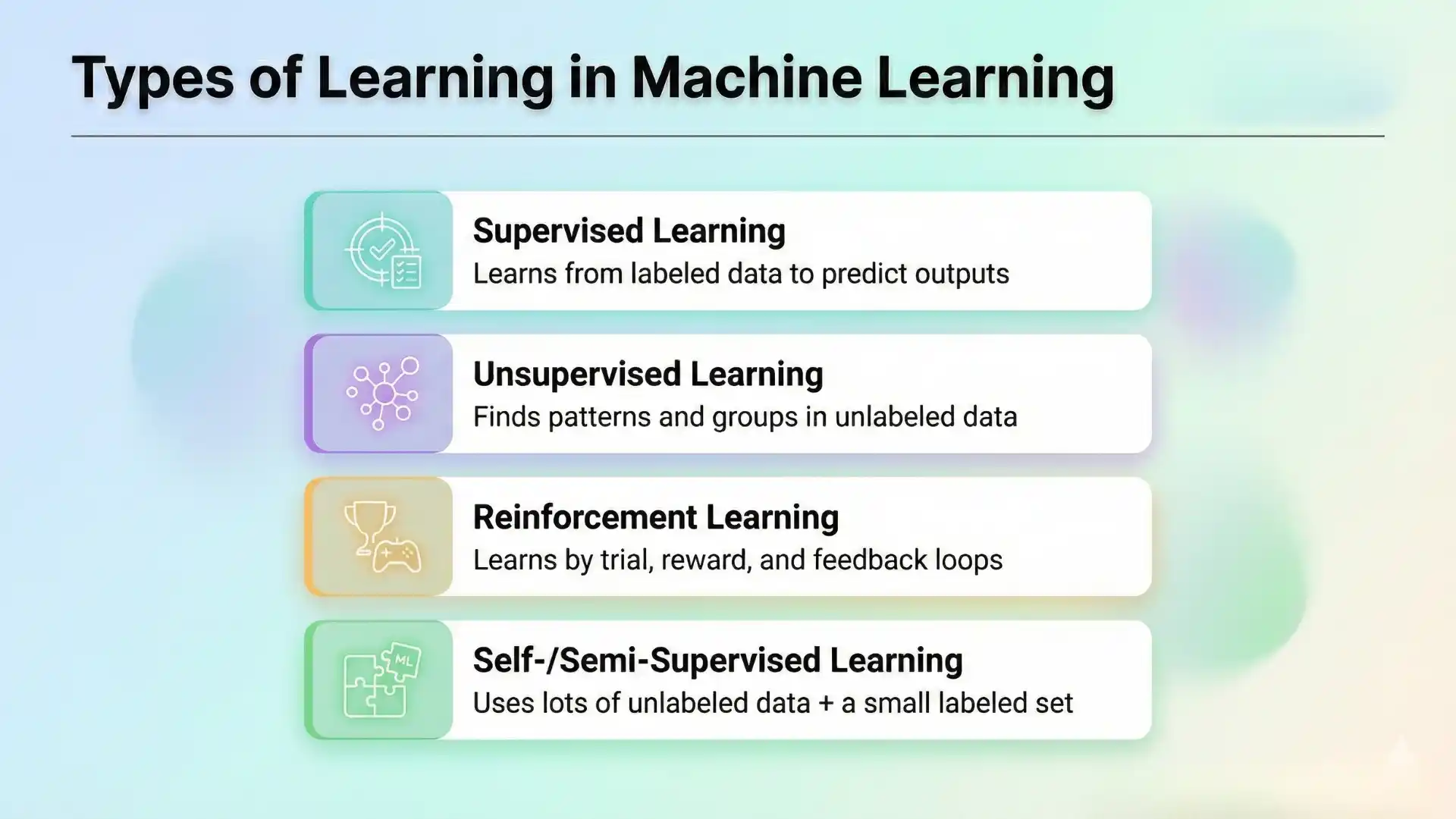
If you have trustworthy labels, start supervised. If labels are missing or expensive, start unsupervised or anomaly detection, and validate carefully before acting on patterns.
Explore Similar Topics: Machine learning vs Deep learning
Types of supervised learning
The most common types of supervised learning are:
- Classification: predict a category (yes/no, A/B/C). These are classification algorithms in machine learning problems.
- Regression: predict a number (time, demand, cost).
Your success metric must match business cost. For rare events, “accuracy” can be misleading; precision/recall trade-offs matter more.
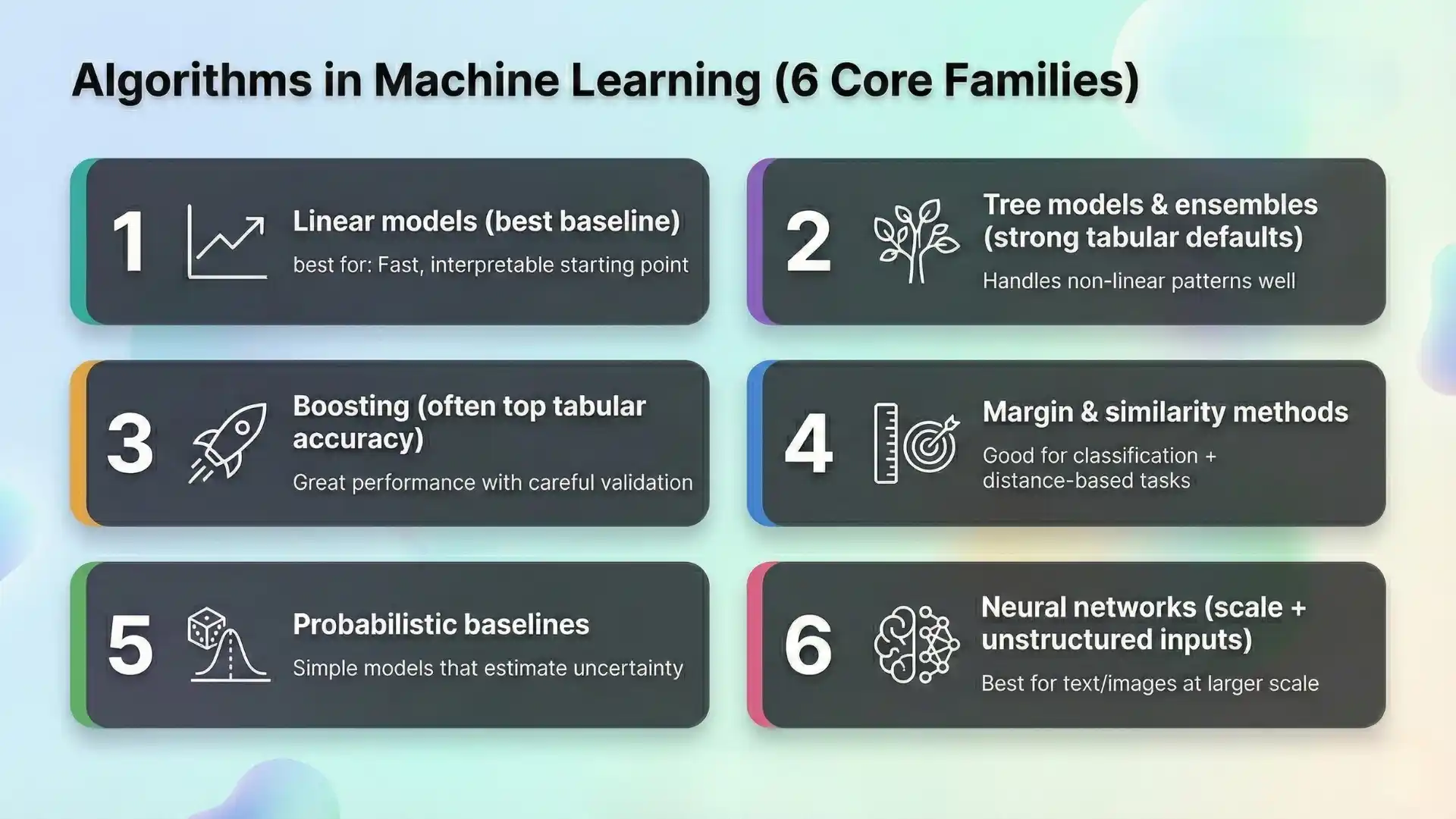
Algorithms in machine learning
Instead of one giant catalog, it helps to group models by what job they do. Below is a curated list of types of machine learning algorithms you’ll see most often, plus where each fits.
1) Linear models (best baseline)
Linear Regression and Logistic Regression are fast, stable, and interpretable. They’re excellent as a first pass and often remain competitive when data is limited. If stakeholders need transparency, linear models are a safe starting point.
2) Tree models and ensembles (strong tabular defaults)
Decision Trees are easy to explain but can overfit. Random Forests reduce overfitting by averaging many trees and usually perform well on tabular data with minimal tuning. For many teams, forests are the first “strong” model after a linear baseline.

3) Boosting (often top accuracy on tabular)
Gradient boosting methods build trees sequentially, focusing on errors made earlier. They often deliver high accuracy on structured data, especially when features are messy and non-linear. The trade-off is sensitivity to leakage and the need for careful validation.
4) Margin and similarity methods
Support Vector Machines can be effective on medium-sized datasets with good feature representations. k-Nearest Neighbors is simple and can work for similarity tasks, but inference becomes slow as data grows.
5) Probabilistic baselines
Naive Bayes is a classic baseline for text classification and count-based features. It’s fast and sometimes surprisingly strong, but its assumptions can limit performance on complex dependencies.
6) Neural networks (scale and unstructured inputs)
Neural approaches can outperform others when you have large datasets or unstructured inputs like text and images. They can also increase cost and operational complexity, so they’re best used when you can prove measurable gains over simpler models.
A practical workflow
Here’s an algorithm sample workflow that is repeatable:
- Define the task, metric, and unacceptable failure modes.
- Build a clean train/validation/test split to prevent leakage.
- Train a baseline (often linear).
- Try one robust upgrade (forest or boosting for tabular; a stronger text model for language).
- Compare results across key segments, not just the overall average.
- Choose the simplest model that meets the bar.
- Deploy with monitoring and a retraining plan.
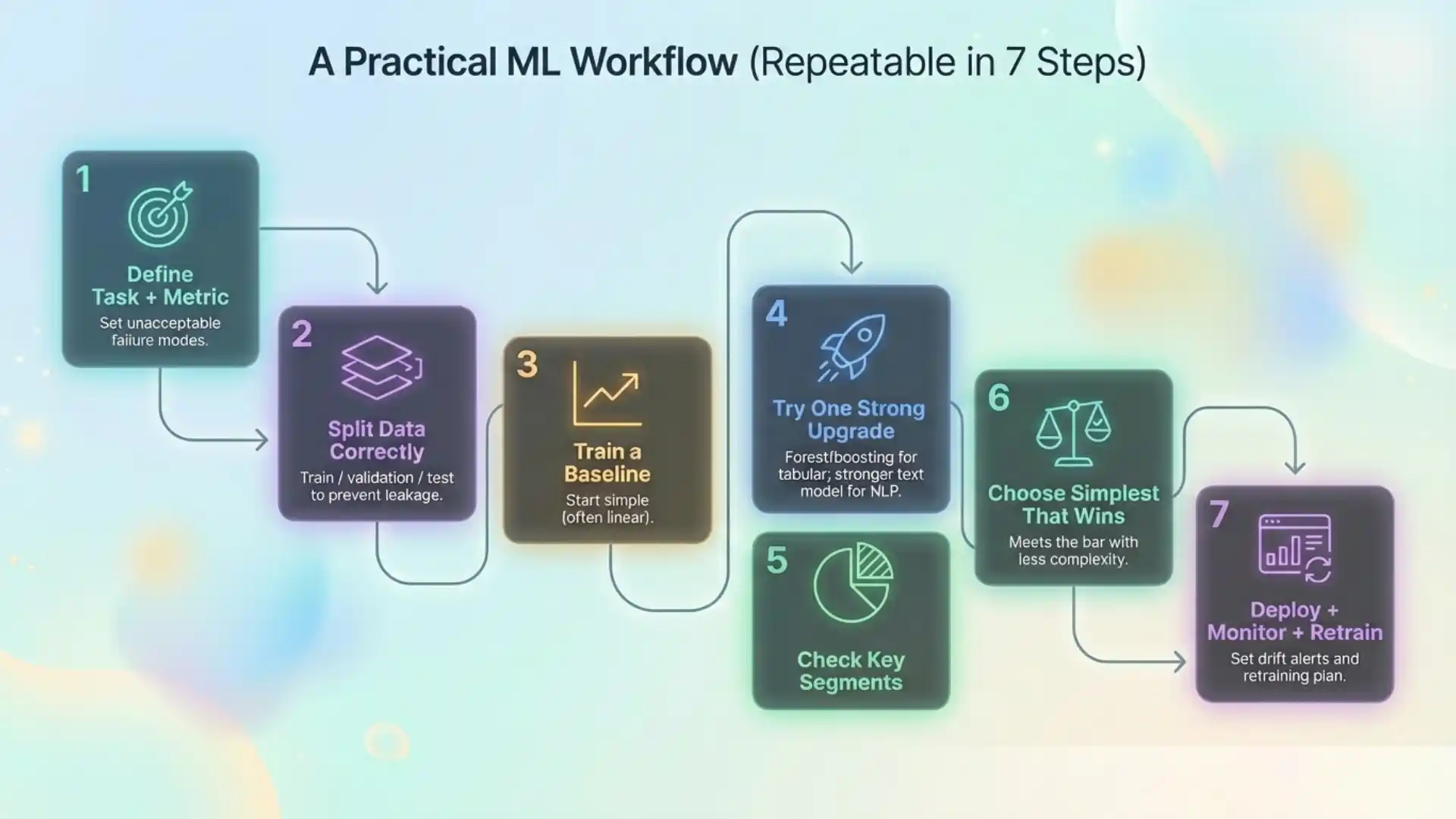
This workflow is part of the basics of machine learning that keeps projects from stalling.
Related Posts: AI and Machine learning in Cybersecurity
Use cases and examples of machine learning
These algorithm examples show how choices map to common problems:
- Churn prediction: start with Logistic Regression, then try boosting if you need lift.
- Fraud detection: boosting is common, but focus on recall/precision and threshold tuning.
- Customer segmentation: start with k-means, then consider density-based clustering if noise is high.
- Anomaly alerts: Isolation Forest is a strong starting point, but thresholds must be calibrated.
- Ticket classification: Naive Bayes is a quick baseline; upgrade only if ROI is proven.
These machine learning examples highlight a pattern: validate first, then optimize.
Common across fintech/ecommerce and SaaS teams (including India/global markets) where churn, fraud, and support automation are high-volume.
Picking the right learning model in machine learning
A learning model is not just a file you ship. It reflects learned assumptions about the world. When the world changes—seasonality, product updates, new user behavior—performance can drift. If your traffic, pricing, or user mix varies by region, monitor segment-level drift (not just overall averages). That’s why monitoring matters: track metrics over time, watch segment breakdowns, and plan retraining triggers.
Across teams, the biggest wins come from consistent machine learning methods: define metrics, prevent leakage, and monitor drift. These methods of machine learning and techniques of machine learning matter more than chasing new ai algorithms. For newcomers, examples for machine learning are easiest when you start with supervised algorithms and compare a few supervised machine learning algorithms as baselines. Over time, you’ll build intuition across types of ml algorithms and choose ml models that fit cost, latency, and explainability. That’s how you turn lists into decisions, and decisions into outcomes.
Final thought: the best model choice in 2026 is rarely the fanciest. It’s the one that meets your metric, fits your constraints, and stays reliable after deployment.
FAQs
1. What is machine learning in simple words?
Machine learning is building software that learns from examples rather than hard-coded rules. You train a model on past data and use it to predict on new data.
2. What are the main types of learning in machine learning?
Most projects fit supervised, unsupervised, reinforcement learning, and self/semi-supervised learning. If labels are trustworthy, start supervised.
3. What are the types of supervised learning?
Supervised learning is mainly classification (predict a category) and regression (predict a number). Choose metrics that match business cost—accuracy can mislead on rare events.
4. Which machine learning algorithm should I start with?
Start with a simple baseline (often linear). Then try one robust upgrade (forest/boosting for tabular) and compare results across key segments before choosing.
5. Why do tree models and boosting work so well on tabular data?
Tree ensembles handle non-linear patterns and messy features with minimal tuning. Boosting often achieves top accuracy, but needs careful validation to avoid leakage.
6. When should I use neural networks?
Neural networks shine with large datasets or unstructured inputs like text/images, but they add cost and operational complexity—use them when they clearly beat simpler models.
7. What matters more than the “best” algorithm in 2026?
A repeatable workflow: define task/metric, prevent leakage, train a baseline, validate across segments, and deploy with monitoring + retraining triggers.
We Also Provide Training In:
- Advanced Selenium Training
- Playwright Training
- Gen AI Training
- AWS Training
- REST API Training
- Full Stack Training
- Appium Training
- DevOps Training
- JMeter Performance Training
Author’s Bio:

Content Writer at Testleaf, specializing in SEO-driven content for test automation, software development, and cybersecurity. I turn complex technical topics into clear, engaging stories that educate, inspire, and drive digital transformation.
Ezhirkadhir Raja
Content Writer – Testleaf
![]()





