In 2026, the biggest shift won’t be “AI can generate test cases.”
That’s already table stakes.
The shift will be this: quality becomes a measurable, AI-augmented system—or it becomes the bottleneck.
The World Quality Report 2025–26 puts a number behind what many QA leaders are already sensing: Generative AI is now the top-ranked skill for quality engineers (63%).
But here’s the uncomfortable truth: tools alone don’t create outcomes. Many organizations are running GenAI pilots that never translate into real, repeatable delivery improvements—often because they don’t integrate GenAI into workflows, metrics, and governance.
In 2026, Generative AI in software testing shifts from experimentation to operationalization. Winning QA teams will define test intent (not just test cases), add evaluation gates (“evals”) in CI, and require self-explaining automation with evidence. The goal isn’t faster output—it’s measurable confidence with governance and ROI.
Key Takeaways
-
Define test intent + oracles so AI-generated tests prove the right outcomes.
-
Add eval gates in CI (golden sets + scoring) before AI artifacts ship.
-
Make automation self-explaining with failure narratives + evidence links.
So instead of another “AI will change testing” article, let’s talk about what will actually change in 2026—and what high-performing QA teams will do differently.
Why 2026 feels different from 2024–2025
2024–2025 was experimentation: prompts, copilots, test generation demos, “AI in QA” talks.
2026 is operationalization. The questions shift from:
- “Can GenAI help?” to “Where exactly does it sit in our SDLC?”
- “Can it write tests?” to “Can it increase confidence without increasing risk?”
- “Is it cool?” to “Can we measure ROI and control failure modes?”
This is where thought leadership matters: the teams that win won’t be the ones with the most tools. They’ll be the ones with the best quality operating model.
CI runners in different regions, geo-specific cookie banners, A/B experiments, and first-time user flows can change what the UI shows. If your product serves India + global traffic, treat these as “state contracts” and test them explicitly—not as flaky surprises.
10 trends that will define GenAI in software testing in 2026
1) Test design moves from “test cases” to “test intent”
What changes: We stop counting test cases and start defining intent, constraints, and oracles.
Why it matters: GenAI can generate quantity. The bottleneck becomes correctness.
Example: “Checkout must never charge twice” becomes an invariant tested across flows.
2) “Self-healing” becomes “self-explaining”
What changes: Instead of silently fixing locators, systems will produce failure narratives:
- what changed,
- what signal supports it (network/console/DOM),
- what fix is most likely.
Why it matters: AI that “heals” without explaining creates hidden risk.
3) AI-driven flaky test triage becomes standard
What changes: AI will classify failures into buckets (app bug vs environment vs test debt) and propose next actions.
Failure mode: Teams accept AI classifications without evidence.
What to do: Require “evidence links” (logs, traces, diffs) in the triage output.
4) Evaluation pipelines (“evals”) become the new unit tests
What changes: GenAI outputs (tests, data, summaries, defect reports) get scored before they merge.
Why it matters: Without evaluation, GenAI becomes a productivity illusion.
What to do: Create “golden sets” of expected outcomes and regression them in CI.
5) Change-impact testing becomes more important than full regression
What changes: Teams prioritize what changed → what might break.
Why it matters: Release velocity won’t slow down. Confidence must become smarter, not bigger.

6) Synthetic test data becomes a first-class artifact (with governance)
What changes: GenAI-generated data sets become reusable assets.
Failure mode: Privacy leaks or unrealistic distributions.
What to do: Treat synthetic data like code: review, version, validate.
7) QA expands into prompt-risk and output-risk testing
If your product uses LLMs, testing now includes adversarial scenarios:
- prompt injection,
- insecure output handling,
- data leakage behaviors.
OWASP explicitly calls out Prompt Injection and Insecure Output Handling as top risks for LLM applications.
2026 prediction: QA and security test plans merge here—whether org charts catch up or not.
8) Agentic testing grows—but many projects get scrapped
Agentic testing (AI agents that plan, execute, and decide) will grow—but also face reality checks: cost, unclear outcomes, and “agent washing.” Reuters reported Gartner’s view that over 40% of agentic AI projects may be scrapped by 2027.
What to do: Keep agency limited. Let agents suggest, not ship, unless the risk is low.
9) Observability becomes part of “testing”
What changes: Quality isn’t only pre-prod. Teams use production signals (SLIs/SLOs, tracing, error budgets) as test oracles.
Why it matters: Modern systems fail in integration edges, not unit-level logic.
10) ROI + governance becomes the real differentiator
Many GenAI initiatives fail not because models are weak, but because integration and measurement are weak.
2026 prediction: Leadership will fund QA teams that can say:
- “We reduced triage time by X%”
- “We lowered defect escape rate by Y”
- “We increased release confidence with measurable signals”

What QA teams will stop doing in 2026
- Writing repetitive test cases from scratch
- Treating automation output as the only “quality signal”
- Running massive regressions without change-impact prioritization
- Accepting AI outputs without evaluation, evidence, or review
- Leaving GenAI risk testing entirely to “security later”
What QA teams will start doing in 2026
- Maintaining eval suites alongside test suites
- Using quality prompts (intent + constraints + oracle definition) as reusable assets
- Building failure narratives as a standard artifact of every run
- Validating AI features with adversarial prompt libraries (red-team sets)
- Tracking confidence with a Quality Metrics Dashboard, not a “pass rate” screenshot

The Testleaf perspective: the “Confidence Stack” for GenAI-era testing
Here’s a simple model that scales better than tool-chasing:
- Intent — what are we proving? (risk-based)
- Evidence — what signals prove it? (logs, traces, checks)
- Evaluation — how do we score reliability? (golden sets, regressions)
- Governance — what’s allowed to be autonomous? (policy + approvals)
If you implement only the “AI generation” layer without evaluation and governance, you’ll create faster output—but not faster trust.
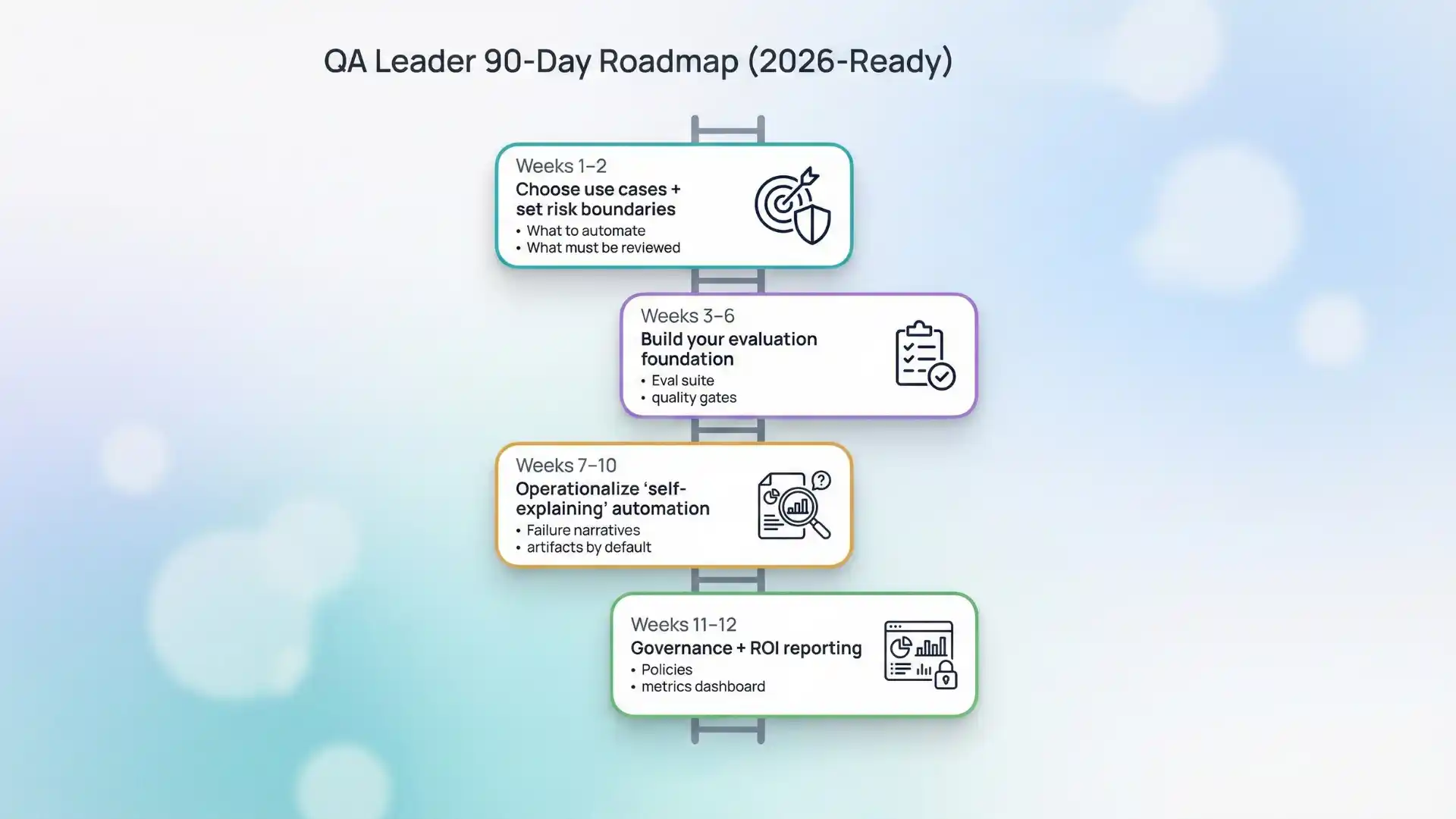
A practical 90-day roadmap for QA leaders (2026-ready)
Weeks 1–2: Choose use cases + draw risk boundaries
- Pick 2–3 measurable use cases (triage summaries, test intent generation, data generation)
- Define where AI can act vs where it can only assist
Weeks 3–6: Build your evaluation foundation
- Create golden sets (expected results)
- Add scoring gates in CI for AI-created artifacts
Weeks 7–10: Operationalize “self-explaining” automation
- Standardize failure narratives
- Connect test results to evidence (logs/traces/diffs)
Weeks 11–12: Governance + ROI reporting
- Approval workflows for high-impact changes
- Dashboard outcomes: time saved, defect containment, release confidence
The biggest prediction for 2026
The most valuable QA professionals won’t be the ones who “use GenAI.”
They’ll be the ones who can answer—calmly, consistently, with evidence:
“Are we safe to ship?”
Because in an AI-accelerated SDLC, confidence becomes the rarest asset.
If you’re building GenAI capability in your QA organization at Testleaf (or anywhere), the goal isn’t more automation. The goal is repeatable confidence—and the operating model to prove it.
If you want to stay future-ready, start building practical skills in Genai in software testing—from intent-first test design to eval gates and evidence-driven QA.
Join our webinar: AI Master Class for QA Professionals – Master AI Agents.
Reserve your spot and learn how to apply these workflows in real projects.
FAQs
1. What is Generative AI in software testing?
GenAI helps create test ideas, data, summaries, and triage outputs—but teams must verify results with eval gates and evidence before trusting them.
2. What will actually change in software testing in 2026?
Testing shifts to intent-first design, eval pipelines in CI, and self-explaining automation—so confidence is measurable, not assumed.
3. What are “evals” in QA and why do they matter?
Evals are scoring checks for GenAI outputs (tests/data/summaries) using golden sets in CI—without them, GenAI becomes a productivity illusion.
4. How should QA test LLM features (chatbots, copilots) safely?
Include prompt-risk and output-risk testing (e.g., prompt injection, insecure output handling) and treat these as part of the test plan—not “later.”
5. Will GenAI replace testers in 2026?
It replaces repetitive work, but increases the need for testers who define intent, risks, oracles, and governance for trustworthy releases.
6. What should we measure to prove GenAI ROI in testing?
Track triage time reduction, defect escape reduction, change-impact coverage, and confidence signals tied to outcomes—not “tests generated.”
7. What’s the biggest mistake teams make with GenAI in QA?
Shipping without evals and evidence. If you don’t score outputs, you can’t trust them.
We Also Provide Training In:
- Advanced Selenium Training
- Playwright Training
- Gen AI Training
- AWS Training
- REST API Training
- Full Stack Training
- Appium Training
- DevOps Training
- JMeter Performance Training
Author’s Bio:

Content Writer at Testleaf, specializing in SEO-driven content for test automation, software development, and cybersecurity. I turn complex technical topics into clear, engaging stories that educate, inspire, and drive digital transformation.
Ezhirkadhir Raja
Content Writer – Testleaf
![]()