
Your test suite is growing. But is your confidence?
Most QA teams don’t notice the problem early.
At first, automation feels like progress:
- more Playwright tests
- more coverage
- more confidence
But a few months later, reality starts to show up:
- pipelines take longer to run
- failures become harder to trust
- debugging consumes more time than writing tests
And yet, the response is almost always the same:
“Let’s add one more E2E test.”
That decision — repeated over time — is how modern test pyramids silently break.
Why are smart QA teams rethinking the test pyramid with Playwright and AI?
Because too many UI-heavy Playwright tests slow pipelines, increase flakiness, and reduce confidence. AI helps teams spot duplication, fragile flows, and better test placement opportunities.
How do Playwright and AI improve test strategy?
Playwright makes modern end-to-end testing fast and debuggable, while AI helps teams analyze runtime, duplication, flaky patterns, and layer imbalance so they can move checks to faster, more stable test levels.
Popular Articles: playwright interview questions
The real issue is not lack of testing. It’s poor test placement.
In mature engineering environments, quality problems rarely come from too few tests.
They come from testing the right things in the wrong layer.
Industry practices and engineering insights from organizations like Google consistently emphasize:
- UI tests are the slowest and most fragile
- lower-level tests (API/component) are faster and more stable
- duplication across layers increases maintenance without increasing confidence

Which leads to a critical shift in thinking:
More tests don’t improve quality. Better test placement does.
Why Playwright accelerates both progress and problems
Playwright is one of the most powerful modern testing frameworks.
It enables teams to:
- build reliable E2E tests quickly
- simulate real user interactions
- debug with rich traces and artifacts
But this strength also introduces a subtle risk:
When writing E2E tests becomes easy, teams start using them for everything.
Instead of balancing the test pyramid, teams unintentionally flatten it — pushing more logic into the browser layer:
- business rules
- UI validations
- edge cases
- API checks
The result?
- bloated test suites
- repeated setup overhead
- fragile cross-system dependencies
Signs your test pyramid is already broken
If your team experiences these, it’s not a scaling issue — it’s a strategy issue:
- Your E2E suite keeps growing, but confidence does not
- Most execution time is spent on login, navigation, and setup
- The same business logic is validated in multiple UI flows
- A small UI change breaks many unrelated tests
- Flaky failures are common and hard to reproduce
- Teams hesitate to refactor because “too many tests might break”
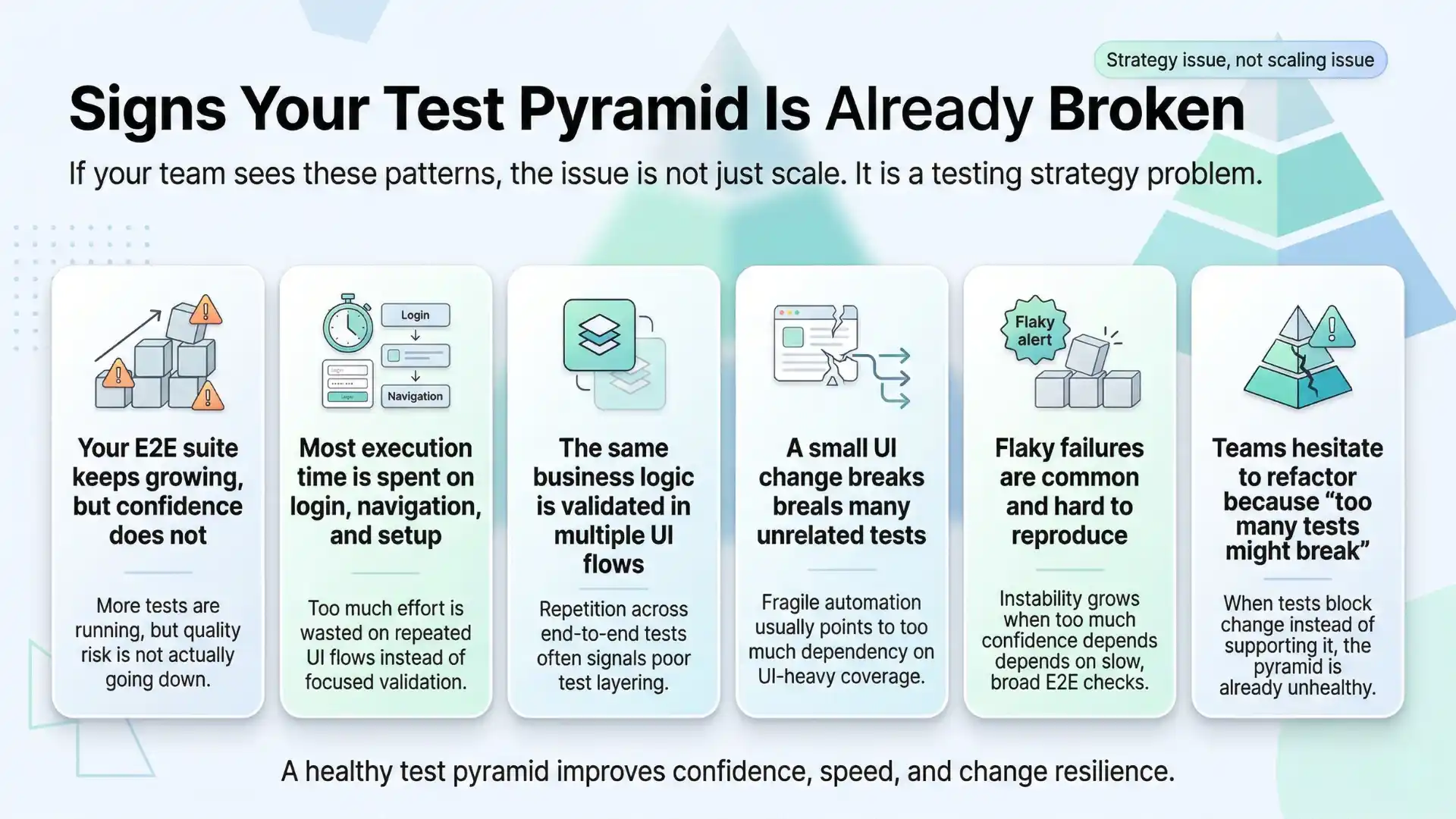
These are classic symptoms of an imbalanced test pyramid.
Broken vs Healthy pyramid
| Signal | Broken Pyramid | Healthy Pyramid |
|---|---|---|
| E2E volume | Keeps growing | Limited to critical journeys |
| Pipeline time | Slow and rising | Predictable and controlled |
| Flakiness | Frequent | Reduced through lower-layer coverage |
| Duplication | Same logic checked everywhere | Clear responsibility by layer |
| Confidence | Low despite many tests | Higher with fewer, better-placed tests |
Where AI actually helps (and where it doesn’t)
There is a lot of noise around AI in testing.
But its real value is not in generating more tests.
It is in helping teams understand their existing test suite better.
AI turns your test suite into a system you can analyze — not just maintain.
Dive Deeper: manual testing interview questions
What AI can realistically analyze
When applied correctly, AI can evaluate:
- runtime distribution across tests
- flaky failure patterns
- overlap between test scenarios
- repeated setup steps
- assertion similarity across flows
- coverage gaps across layers
This is where human intuition alone often falls short.
What AI-driven test pyramid optimization looks like
Instead of relying on gut feeling, teams get data-backed recommendations.
Scenario 1: Overloaded E2E coverage
Observation:
Multiple Playwright tests validate pricing logic through full checkout journeys
Insight:
Most runtime is spent on setup, not validation
Recommendation:
- keep a few critical E2E journeys
- move pricing combinations to API tests
- validate UI states at component level
Scenario 2: Repeated setup across tests
Observation:
Tests repeatedly perform login and navigation for small UI checks
Recommendation:
- reuse state using fixtures
- move isolated checks into component tests
Scenario 3: Flaky multi-system flows
Observation:
Large E2E tests fail due to multiple dependencies
Recommendation:
- split validations into lower layers
- keep one minimal end-to-end smoke path
A practical framework: The AI Pyramid Review Model
To make this actionable, modern QA teams follow a structured approach:
1. Observe
Collect metrics — runtime, failures, duplication
2. Classify
Identify which layer each test truly belongs to
3. Recommend
Use AI insights to suggest better placement
4. Protect
Keep only high-value user journeys at E2E
5. Review
Apply human judgment before making changes
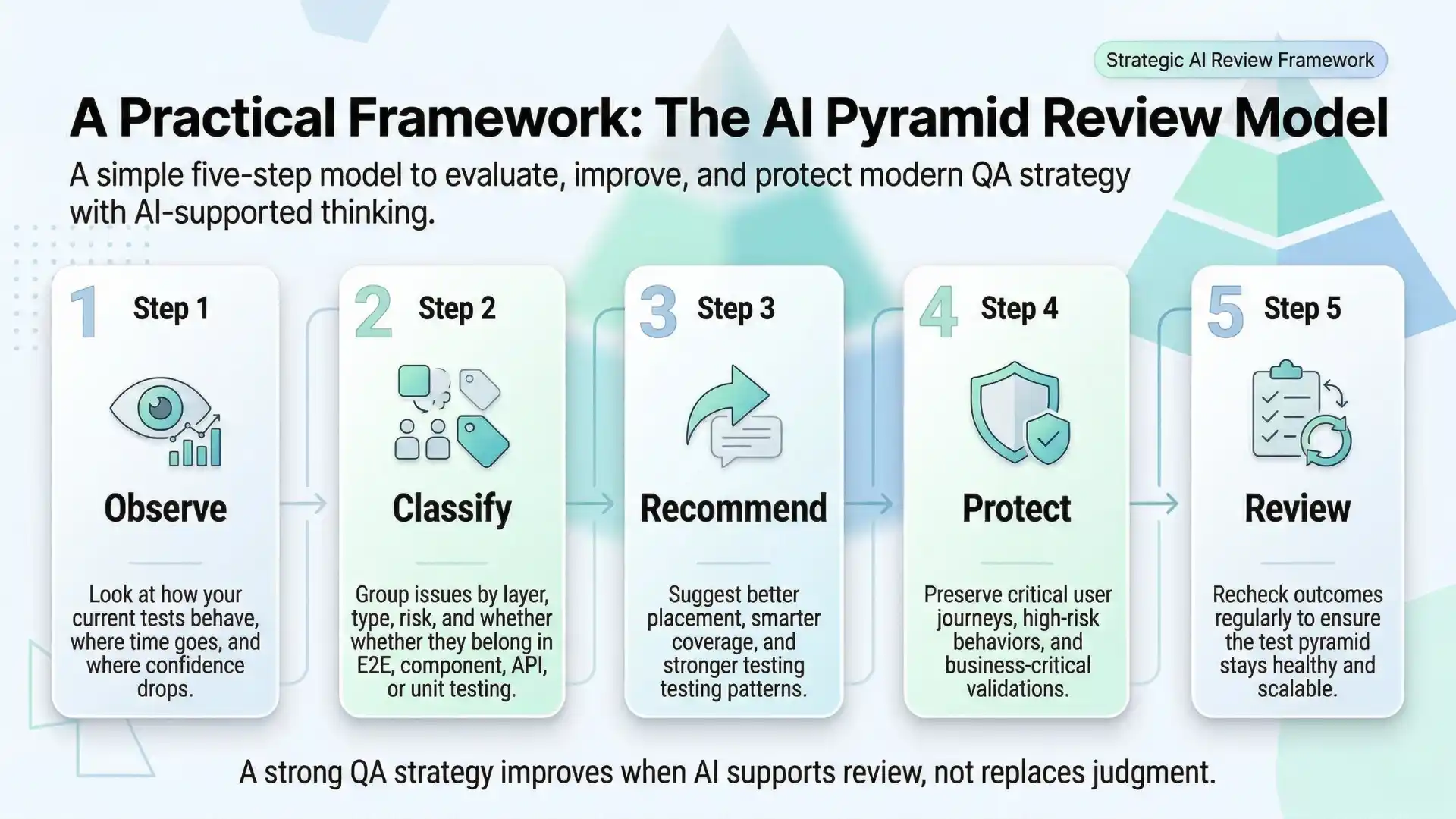
This balance is critical:
AI recommends. QA decides.
Why this matters beyond testing
Test pyramid optimization is not just a technical improvement.
It directly impacts business outcomes:
- faster releases due to shorter pipelines
- lower infrastructure costs
- reduced debugging time
- higher trust in automation results
Engineering insights from companies like Microsoft highlight a consistent pattern:
A significant portion of development time is spent diagnosing failures rather than building features.
Reducing unnecessary E2E complexity directly addresses this inefficiency.
You Should Also Read: Java selenium interview questions
Guardrails: What AI should never do
To maintain trust and reliability, AI must be used responsibly.
It should never:
- remove tests automatically without review
- optimize only for speed while ignoring risk
- eliminate critical business journeys
- replace human judgment in test strategy
The goal is not fewer tests.
The goal is smarter, better-placed tests.
The shift happening in modern QA teams
High-performing QA teams are changing how they think.
They are no longer asking:
“Should we add another Playwright test?”
They are asking:
- Is this test in the right layer?
- What value does this test provide?
- Are we validating behavior or repeating flows?
This shift — from volume to strategy — defines modern quality engineering.
Key Takeaways
- Keep only high-value business journeys in E2E
- Move repeatable logic to API and component tests
- Use AI to recommend, not auto-delete
- Let QA review every structural change
Final thought
A strong test pyramid does not happen by accident.
It requires:
- continuous evaluation
- disciplined test placement
- and the ability to challenge existing patterns
Playwright gives teams the capability to test modern applications effectively.
AI gives them the clarity to do it intelligently.
Together, they enable what every QA team ultimately wants:
High confidence with minimal waste.
Closing
If your Playwright suite is growing but not improving, the problem is not the tool.
It is the strategy.
And that’s where modern QA thinking — and platforms like Testleaf — are helping teams build quality that scales.
FAQs
What is test pyramid optimization in Playwright?
Test pyramid optimization in Playwright is the process of balancing E2E, API, and component tests so pipelines stay fast, stable, and easier to maintain.
Why are too many Playwright E2E tests a problem?
Too many Playwright E2E tests increase execution time, create duplication, make failures harder to debug, and often reduce confidence instead of improving it.
How does AI help improve the test pyramid?
AI helps by analyzing runtime, flaky failures, repeated setup, overlap between scenarios, and coverage gaps so teams can make better test placement decisions.
Can AI reduce Playwright test flakiness?
Yes. AI can identify flaky patterns, unstable flows, and layer imbalance, helping teams move fragile checks to faster and more stable lower-level tests.
Which tests should remain end-to-end in Playwright?
Critical business journeys that need full user-flow validation should remain end-to-end in Playwright, while repeatable logic should move to API or component layers.
What is the AI Pyramid Review Model?
The AI Pyramid Review Model is a practical framework with five steps: Observe, Classify, Recommend, Protect, and Review.
What should AI never do in test strategy?
AI should never remove tests automatically, ignore business risk, eliminate critical journeys, or replace human judgment in test strategy decisions.
Why are smart QA teams rethinking the test pyramid now?
Smart QA teams are rethinking the test pyramid because growing UI-heavy suites slow pipelines, increase fragility, and create maintenance overhead without proportional confidence.
We Also Provide Training In:
- Advanced Selenium Training
- Playwright Training
- Gen AI Training
- AWS Training
- REST API Training
- Full Stack Training
- Appium Training
- DevOps Training
- JMeter Performance Training
Author’s Bio:

Content Writer at Testleaf, specializing in SEO-driven content for test automation, software development, and cybersecurity. I turn complex technical topics into clear, engaging stories that educate, inspire, and drive digital transformation.
Ezhirkadhir Raja
Content Writer – Testleaf
![]()





